
这是我学习Cisco CCNA的笔记,虽然现在思科的设备在国内应该说应用不多了,但对于学习网络基础知识还是非常有帮助的。
重点摘要
OSI、TCP/IP
封装的详细过程
交换机
研究网络层报头
研究传输橙报头
研究数据链路层帧头
网络的定义
介质:一般指双绞线
中间系统:网络设备
终端系统:一般指PC和服务器
1).一组使用介质(线缆)互联的中间系统(网络设备)以及终端系统(PC和服务器)
2).工作组(Network Group),微软定义的最早期的网络雏形,可以理解为它是一个局域网范畴.是最简单的,范围最小的局域网
网络的意义
通过让应用程序之间彼此传递信息,从而实现资源共享.
一些网络术语
speed(速度):物理特性,例如10Mbit/s
cost(开销):计算某种协议到达目标的最短距离称之为开销
security(安全性):IPSEC VPN,MPLS VPN,SSH,...
availability(可用性):衡量设备在投入使用后实际使用的效能
reliability(可靠性):系统在一定时间内,在一定条件下无故障的执行指定功能的能力
10Base2:使用提供10M带宽基带传输的同轴电缆中的细缆
10Base5:使用提供10M带宽基带传输的同轴电缆中的粗缆
10BaseT:使用提供10M带宽基带传输的双绞线
拓扑类型
物理拓扑:物理连线
逻辑拓扑:逻辑拓扑主要是用来描述网络设备间流量经过的路径
总线型拓扑:将PC服务器连接到服务器上的连接方式称为总线型拓扑
星型拓扑:通过交换机互联的连接方式称为星型拓扑
集线器
1).带宽:一个接口在单位时间内,能够接受和发送多少数据.带宽直接影响网络体验,在网络中带宽单位为bit/s,换算成浏览器下载速度要 /8,带宽描述的是速率
2).延迟(delay):延迟描述是的是速度,从发送端发送数据帧开始计时,到接受端收到数据帧后停止计时,这个时间段就叫做延迟,集线器只提 供10Mbit/s带宽
3).共享带宽:网络设备无论连接多小台PC,每台PC能够使用带宽会受到数量的增加而成倍减小,当只有一台PC时,此时它独享带宽
4).独享带宽:网络设备无论连接多小台PC,每台PC能够使用带宽完全一样,不会受到数量的增加而减小
5).双工模式(duplex):描述一根介质双向的传输性
6).单工模式:通过这个链路永远只有一个方向的流量(例如光钎)
7).半双工模式:任何时间内只能有一个方向的流量存在于线缆之上
8).全双工模式:任何时间内,流量在线缆上都可以双向传输集线器的接口永远只支持半双工传输,所有链接集线器的线缆都只能工作在半双工模式中
9).集线器是一层设备(物理层)它无法识别任何控制信息.转发机制为放大信号+泛洪处理,所有链接集线器的设备同处一个冲突域
10).冲突域:冲突产生的时候能够接受到冲突碎片的设备的集合就是冲突域,产生冲突的必要的两个原因,一个是泛洪,一个是半双工,交换机的接口 可以分割冲突域
11).集线器收到任何报文,都会泛洪,可以理解为集线器的转发机制就是泛洪
12).泛洪的意义:将一个报文拷贝若干份,发给除了接收者接口之外所有其它接口
13).集线器的接口不能切分任何域
主机到主机之间的通信原则
1).网络中的通信都是端到端的通信,我们称之为End-To-End
2).在以前网络设备因为每个厂商所使用的协议不同,开发出来的网络设备的互相不能兼容,为了解决这个问题ISO组织就站出来制定了一套协议标准,就是我们后来的
OSI参考模型,由于OSI是个协议栈,里面包含了成千上万个协议,为了使网络看起来比较清澈明了一点,ISO把OSI分成7个区块,7个区块彼此之间没有任何的重叠,我们
把这几个区块称之为OSI地七层模型,OSI七层模型从上往下依次为,应用层,表示层,会话层,传输层,网络层,数据链路层,物理层
3).分层提供了如下好处:
1.减少网络的复杂度
2.标准化
3.模块化
4.协作
5.加速发展
6.简单教学
4).我们把OSI上三层称之为系统层,下四层称之为网络层,OSI定义的服务是下层为上层提供服务
OSI(理想是丰满的)协议栈
1).第7层.应用层:应用层为我们的应用程序提供服务,我们可以理解为所有能够上网的应用程序都是应用层的内容
2).第6层.表示层:表示层在应用程序传输数据之前在双方的操作系统之间协商彼此支持的编码解码格式,压缩解压缩格式,加密解密格式 etc.. 导致我们的乱码能够
被屏蔽,表示层就是为应用层提供服务.
3).第5层.会话层:会话层只有3个用途:
1.在通信开始之前帮应用程序到应用程序之间建立一个逻辑通道
2.在传输数据的时候帮应用程序维护这个信道
3.数据传输完成后帮应用程序把信道拆开
4).第4层.传输层:封装是从4层传输层开始到二层数据链路层结束
1.传输层会把会话切片,传输层会把长串的数据切分成若干个小的分片,来满足MTU规则(<=1500字节),好让网卡把每个分片发送出去,能 让网卡一次性把每个分片发送出去
2.封装控制信息,在每个数据分片前面加控制信息,我们把传输层所添加的控制信息打一个包,称之为报头(传输层报头,段头,4层报头),报头中包含了一
系列控制信息,其中我们4层报头所添加的控制信息中最重要的是哪个应用程序发的-哪个应用程序收(使用端口号来唯一的标识我们的应用层的应用程序)
在传输层中的控制信息中包含了源端口号sport和目的端口号dport,端口号字段长度为16bit,用十进制来表示为0-65535,1-1023为知名端口号,1024-65535为非知名端
口号,对于一台PC而言,所有的应用程序对应一个端口号是唯一的,因为端口号用来唯一的标识一个应用程序,传输层在数据分片的前端添加了一个报头之后形成了一
个PDU(协议数据单元),PDU对于4层而言称之为数据段,数据段不能被直接发送,因为报头中只有源目端口号,光凭源目端口号无法唯一的定位网络中的一股流
5).第3层.网络层:网络层对传输层的数据段添加了一些新的控制信息,这些新的控制信息我们称之为3层报头,在3层报头中最重要的就是源目3层 信息(IP地址信息,
逻辑地址信息)用来标识网络中的一个节点,数据段在添加了3层报头之后被称之为数据包(packet),因为交换机无法识别 3层和4层的控制信息,所以我们的数据包无
法被直接发送,这时候就需要添加2层的控制信息,源目MAC地址
6).第2层.数据链路层:会在整个3层数据包的基础上添加2层报头(链路层报头,以太网帧头),并且在最后添加一个FCS,在2层报头中包含源 目MAC地址,有了源目MAC地
址之后,交换机就不会傻泛洪,节约了网络带宽,提高了网络的可用性,这时候数据帧还是不能被转发,因为我们需要传输介质.
11).第1层.物理层:物理层在接受到数据链路层发下来的数据帧会把它转换成bit,把bit转换成脉冲信号,通过传输介质发送出去,2层的数 据帧才是在网络中传输的唯一一种单元
数据封装的详细过程
数据封装就是从OSI参考模型的第四层开始的,到第二层逻辑链路层结束
传输层会封装控制信息,它会在每个数据分片前面加一个控制信息(我们把传输层所添加的控制信息打一个包,称之为报头(传输层报头,段头,4层报头))
4层报头所添加的控制信息中最重要的是哪个应用程序发的-哪个应用程序收(使用端口号来唯一的标识我们的应用层的应用程序)
在传输层中的控制信息中包含了源端口号sport和目的端口号dport,端口号字段长度为16bit,用十进制来表示为0-65535,1-1023为知名端口号,1024-65535为非知名端
传输层在数据分片的前端添加了一个报头之后形成了一个PDU(协议数据单元),PDU对于4层而言称之为数据段,数据段不能被直接发送,因为报头中只有源目端口号,光凭源目端口号无法唯一的定位网络中的一股流
|
|
|
接下来传输层会将数据段发送给第3层网络层,网络层对传输层的数据段添加了一些新的控制信息,这些新的控制信息我们称之为3层报头,在3层报头中最重要的就是源目3层信息(IP地址信息,逻辑地址信息)
用来标识网络中的一个节点,数据段在添加了3层报头之后被称之为数据包(packet),因为交换机无法识别 3层和4层的控制信息,所以我们的数据包无法被直接发送,这时候就需要添加2层的控制信息,源目MAC地址
|
|
|
数据链路层:会在整个3层数据包的基础上添加2层报头(链路层报头,以太网帧头),并且在最后添加一个FCS,在2层报头中包含源目MAC地址,有了源目MAC地址之后,交换机就不会傻泛洪,节约了网络带宽,提高了网络的可用性,
这时候封装就已经结束了,剩下的只需要将数据分片下发给物理层(1层)就可以了.
总结:
封装过程:传输层(4层),添加源目端口号-->网络层(3层),添加源目ip地址--->数据链路层(2层),添加源目MAC地址
网络层(3层)报头,称为数据包(packet)
数据链路层(2层)报头,称为数据帧,二层的数据帧(frame)才是在网络中传输的唯一单元
报头是添加在数据分片的最前端:因为控制信息只是给中间系统看的,所以打在前端方便中间系统查阅,直接减小了端到端的延迟
给数据分片添加4层报头、3层报头、2层报头的行为叫做数据封装
TCP/IP(现实是骨感的)协议栈
1).第四层,Application:Application对应OSI的上3层,TCP/IP的应用层,包含的就是能上网的应用程序以及上层 协议.
2).第三层,Host-To-Host:Host-To-Host对应OSI的传输层.
3).第二层,Internet:Internet对应OSI的网络层.
4).第一层,Network Intferface:对应OSI的数据链路层和物理层.
TCP/IP与OSI参考模型的相同点/不同点
1).唯一的一个相同点TCP/IP和OSI都是协议栈,里面都包含了成千上万的协议,Internet想要正常的运作,都需要让所有的中间系统 和终端系统都能够支持这些协议
1).不同点:
1.TCP/IP协议站和OSI协议站没有一个重复的协议,一个仅用于理论,一个用于实践
2.封装形式不同,OSI会在所有应用程序产生的流量到达传输层,都要进行第一步封装添加一个4层报头,然后到达网络层添加3层报头,再到达数据链路层,添
加一个帧头和一个帧尾,所以在网络中发送的全都是经历过3次封装的数据帧,我们把这种行为称为逐层封装.而TCP/IP的封装机制叫做越层封装,基于不同的
应用程序产生的流量在被发送之前可能添加的报头信息可能不一样,不同的协议产生的流量在发送之前经历的封装次数可能不一样,这种封装机制是TCP/IP
协议与OSI协议的最本质的区别
TCP/IP每层常使用的协议
1).Application.应用层:
a.HTTP,用于浏览网页,基于TCP端口号80.往返的报文都是以明文形式发送
b.HTTPS,安全的超文本传输协议,用来安全的浏览网页,往返的报文都是加密的,基于TCP端口号443
c.FTP,文件传输协议,用来高速的上传和下载大批量的数据文件,基于TCP的20,21,FTP属于双信道协议,一般我们把双信道协议的端口号做一 个分类,一个叫做
控制端口号,一个叫做数据端口号,FTP的数据端口号20用来在PC和服务器之间建立一个FTP逻辑信道,一般使用20端口发送 的都是一些基于FTP的信令流量,信令流量
帮我们打通一个虚拟的逻辑连接,然后再使用FTP控制端口号21在信令信道的基础之上传递我们的数据
d.DNS,域名解析服务,用来将PC访问网页的URL转换为IP地址,基于UDP端口号53.
e.SMTP,简单邮件传输协议,用来发送E-MAIL,基于TCP端口号25.
f.POP3,邮局协议第三版本,用来接受E-MAIL,基于UDP端口号110.
g.Exchange:企业级应用邮箱服务,既可以用来收邮件,也可以用来发邮件,它是一个私有协议,由某些厂商定义,而并非标准化组织定义,该厂商定 义的协议只有该厂商
的设备可以使用,公有协议,由标准化组织定义,所有厂商都可以使用的协议
h.DHCP,动态主机配置协议,用来让PC和服务器以及网络设备能够自动的接收IP地址,子网掩码,网关地址等等,它基于UDP端口号68
i.TFTP,简单文件传输协议,用来传输小批量的数据文件,通常用于管理网络设备的IOS操作系统以及配置文件,基于UDP端口号69.
j.Telnet,终端仿真协议,用来让网管PC可以通过互联网远程的网管网络设备,基于TCP端口号23.往返的报文都是以明文形式发送,也就是说该 协议不安全.
k.SSH:安全外壳,用途和Telnet一样,仅仅是加密网管会话而已,该加密是基于RSA的,基于TCP端口号22.
l.简单网络管理协议,该协议用来让网管PC可以同时网管整网所有网络设备
m.NTP,网络时间协议,让网络设备和NTP服务器同步网络时钟,基于UDP端口号123
2).Host-To-Host:
2.1)面向连接服务(可靠传输),保证无拥塞,保证数据分片无乱序,保证不丢包,保证数据帧的完整性,当传输出现问题的时候是否支持重传
2.2)无连接服务(尽力而为的传输),不保证能不能到达对端,不保证数据分片是否乱序,不保证数据帧的拥塞
a.TCP(传输控制协议)面向连接协议TCP的长度通常为20-60个Byte,提供可靠的应用程序数据流的转发工作,TCP中最经典的控制信息:
a.1)Window窗口字段用来防止基于TCP的应用程序数据流传输时的拥塞.所有基于TCP的应用程序在传递数据之前都要建立一个3次握手连接,
3次握手的过程---首先由客户端发起一个SYN同步报文---服务器回应一个SYN+ACK半确认半同步报文---Client返还的ACK报文,三次握手用
来协商一系列参数:
1).Window机制就是其中的参数之一,所谓的Window机制就是限制基于TCP应用的发送端每一次能够发送多少流量单位Byte,每一次传输Window大
小都在改变,我们称之为滑动Window,Windows的变化基于当前的网络状况,基于滑动窗口,基本95%以上的基于TCP的应用程序在传输的时候都会
基于一个叫做TCP慢启动(TCP Slow Start),一般基于慢启动的应用程序在协商Window大小的时候,第一次为2^0,当传完1Byte的时候得到一个
ACK回包的时候重新协商 Windows为2^1,以次类推,每一次传输都会让Window增加2倍,当Window大小达到极限时,为了解决拥塞,会重新协商
Window大小,为之前的一半,这就是所谓的TCP慢启动
2).TCP使用Sequence序列号字段来防止数据分片乱序,数据分片在传输中的延迟不同,导致数据分片到达对端的顺序改变,我们把这个行为称之为
抖动(Jitter)
3).TCP使用ACK(确认号),防止传输丢包
4).TCP使用CheckSUM(校验和),来提供完整性检查
5).重传机制:Sequence和ACK一并完成的
b.UDP(用户数据报协议),该协议是一个无连接协议,不提供可靠性,它之提供源目端口号,UDP的优点:
b.1)比较安全,因为UDP不会进行三次握 手,所以不会被DOS攻击,所以相比之下UDP比TCP安全
b.2).三次握手会增减延迟,而UDP不会进行三次握手,所以UDP延迟比较低
b.3).因为UDP的长度为8个Byte,对于载荷比较小的应用程序,UDP更能节省带宽
b.4).UDP不支持重传机制
c.ICMP(因特网控制消息协议),包含了一系列配合IPV4使用的网络工作,其中比较经典的是Ping,Ping由两个报文组成一个是Echo Request另一个是Echo Reply.
d.RTP(实时传输协议),一般配合UDP一并使用,主要用于VOIP环境,因为UDP没有序列号,无法防止乱序,为语音和视频流量提供一个序列组, 为VOIP流量提供防乱序功能,因为该协议定义了序列号
3).Internet:所有在Internet层,提供3层逻辑地址的协议都称之为被路由协议
a.IPV4(因特网协议版本4),该协议主要用途就是定义了IPV4地址,该地址长度为32bit,点分十进制表示,使用4段,每段取值0-255十 进制数,
b.IPV6(因特网协议版本6),该协议主要用途就是定义了IPV6地址,该地址长度为128bit,冒号分十六进 制,XXXX:XXXX:XXXX:XXXX:XXXX:XXXX:XXXX:XXXX
c.IPX
d.AppleTalk
e.Novell
f.DEC
g.PPPoE(PPP Over Ethernet)提供认证授权审计,防止用户蹭网
4).Network Interface:
Network Interface包含Internet环境中的所有的局域网和广域网协议Task.局域网协议(局域网协议使用的介质是固定的,局域网固定线缆上只能跑固定的协议):
a.LAN,
b.Ethernet,以太网协议有两个版本Ethernet2和IEEE 802.3,对人类最大的贡献就是提供了MAC地址,Ethernet环境把整个Internet网段分为2类,一个叫点到点网段
(一个网段内有且只用2 个节点),一个叫MA网段(一个网段内用多个节点),MAC地址就是在MA网段中唯一的标识一台PC.
c.Token Ring,令牌环,基于交换机连接,效率比较低.
d.FDDI,光纤分布数据接口,虽然把FDDI归结为局域网协议,但是我们经常使用FDDI来连接城域网,因为它使用光纤,带宽比较高,传输距离比较远
e.Task.广域网协议(广域网协议都是承载在串行线缆上的(Serial),所有协议都可以跑在串行线缆上,串行线缆默认支持HDLC协议):
e.WAN
f.HDLC(高级数据链路控制协议),
g.PPP(点到点协议),所有点到点,内部集成AAA认证(AuthenticationAuthorization Acconting)
h.Frame Relay(帧中继):让相隔甚远的多个节点的外网接口能够逻辑的在同一个网段内,帧中继是100%支持QOS的二层协议
i.ATM(异步传输模式):也能提供VPN解决方案,但是ATM所提供的带宽远要比帧中继高很多,拥有完美的QOS(服务质量)报账(Quality of Service,通过把internet环境
中的各种各样的不同流量,划一个369等,在网络传递这些流量的时候,优先级较高的流量能够被优先传递,优先 级较低的流量被较差的传递)
研究OSI物理层
OSI物理层定义了:
1.介质类型
局域网环境:Ethernet
双绞线:橙白,橙,绿白,绿,蓝白,蓝,棕白,棕
双绞线内部有8根线,两两交叉,为什么要把线缆两两绞在一起?就是为了增加抗噪能力(干扰),防止串线
双绞线类型:
按照屏蔽与否:
屏蔽双绞线:简称STP,在内部8根线多了一个屏蔽层,这个屏蔽层可以让数据受到干扰的影响要小一点,STP传输距离25米
内屏蔽双绞线:简称SCTP,在内部每两根线使用一个屏蔽层,这样每两根线受到干扰的概率越小,一般如果使用屏蔽双绞线都是使用内屏蔽双绞线居多
非屏蔽双绞线:简称UTP,在8根线外面只有一个外皮,UTP传输距离100米
在做综合布线时,使用STP还是UTP主要考虑传输距离和花费,花费时根据线缆的柔韧程度来决定的,你的线越粗越硬,你的花费一般就越高,你的线越细越柔软花费一般越低
按照介质的带宽:描述一个网段的带宽:接口带宽+线缆带宽
1类:无法传输Ethernet数据,一般用于电信领域
2类:无法传输Ethernet数据,一般用于电信领域
3类:可以用于Ethernet数据传输,该线缆最大带宽10Mbit/s,一般建议在总线型拓扑中使用
4类:可以用于Ethernet数据传输,该线缆最大带宽16Mbit/s,一般还是把它用于总线型拓扑使用,多余的6M全部被浪费
5类:可以用于Ethernet数据传输,该线缆最大带宽100Mbit/s,一般用于星型拓扑使用
5E类:可以用于Ethernet数据传输,该线缆最大带宽1000Mbit/s,一般用于交换机连路由器以及交换机与交换机互联的时候(当前使用最多)
6类:可以用于Ethernet数据传输,该线缆最大带宽1000Mbit/s,和5类线没什么区别,只是工艺上比较高
7类:可以用于Ethernet数据传输,该线缆最大带宽1000Mbit/s,和5类线没什么区别,只是工艺上比较高
8类:目前好像还没出
按照用途分类:
EIA/TIA标准化组织定义的568-A标准:绿白,绿,橙白,蓝,蓝白,橙,棕白,棕
EIA/TIA标准化组织定义的568-B标准:橙白,橙,绿白,蓝,蓝白,绿,棕白,棕
直通线:如果一根双绞线,两端的线序都是568-B,我们称之为直通线
交叉线:如果一根双绞线,两端一边是568-A,一边是568-B,我们称之为交叉线
我们把网络设备分为2大类:交换机,集线器分为一类,路由器,PC,服务器分为另一类
同类设备互联使用交叉线
异类设备互联使用直通线
互联网中双绞线:
双绞线只要是在10M或100M环境下,那么它就只使用4根纤芯,来实现数据传递,其中两根专门用于发,两根专门用于收,1、3线序用来发送流量,2、6线序用来接收流量
双绞线在1000M的环境下:8根纤芯全部都使用,四发,四收,8根纤芯既可以用来传输数据,又可以用来提供电量(POE)
同轴电缆:为有线电视传输电信号,它一般只用于广电网络
粗缆:一个粗,一般用于早期的Ethernet环境,布线成本高,在现今的环境中用的比较少,唯一的优势是传输距离500M,最大带宽10M
细缆:一个细,最长传输距离只有185M(理论上是200M),最大带宽10M
光纤(xian):
单模光纤:只能通过一种入射角度来实现全反射传输
多模光纤:可以通过多种入射角度来实现全反射传输
多模光纤最大只支持1000Mbit/s,而单模光纤支持10000Mbit/s
多模光纤理论最长传输距离为1公里,而单模光纤理论最长传输距离为100公里
所以单模光纤比较好,但是单模光纤比较贵
交换机都具有光模块,早期的GBIC(我们称为大卡),现如今的SPF(我们称为小卡)
连光纤就连两根,其中一根用来发,一根用来收(单工模式的介质)
2.连接器类型
RJ45:又称之为水晶头,一般用于双绞线使用
BNC:一般用于同轴电缆中的粗缆使用
N型反转接头:一般用于同轴电缆的细缆使用
SC:有的时候可以使用在单模关系,有时也可以使用在多模光纤
ST:有的时候可以使用在单模关系,有时也可以使用在多模光纤
光纤接头一般在融好后立即接入光纤,它必须在无尘的环境下进行,因为光纤不允许有灰尘的存在
3.信令类型:一组控制信号,例如CSMA/CD,信令主要起到一些控制作用
用户端信令:在人机中间传递的控制信号,告知用户下一步该做什么.
局端信令:在设备和设备之间传递,用来控制设备对数据流量的传递规则.
研究数据链路层帧头
数据报头:
二层报头:二层报头中比较经典的就是以太网(Ethernet)帧头,它包含如下字段:
对于私有协议(早期的):Etheret2
Preamble:导前码,一共有8byte,在以太网中传输的不仅仅只有数据帧,还会有信令之类的等等信息,那么一个接口它如何判断哪个数据是数据帧,哪个数据是信令呢?换而言之,怎么判断哪个数据该接收?哪个数据不该接收呢?
其实就是基于这个导前码来决定的,导前码中不包含任何控制信息,它仅仅作为一个提示符,来告诉接口该数据是数据帧还是信令或其他等等,所以一般我们不把导前码看做是二层数据帧中的字段
Dest add:目的MAC地址,一共有6byte,为什么6个字节?MAC地址48位嘛
Source Add:源MAC地址,一共有6byte,为什么6个字节?MAC地址48位嘛
Length:长度,一共有2byte,用来描述二层数据帧所封装的三层数据包的长度(它有没有满足MTU标准(<1500字节))
Data:完整的三层数据包(packet)
FCS:换机在发送一个数据帧的时候,为了数据帧不被篡改它会把帧头的所有byte(16byte)做一个MD5的散列计算(hash),得出一个4字节的散列值,装入到数据包的帧尾,交换机发送的任何报文都会携带FCS
而交换机在接收到一个报文的时候,为了检测这个数据包有没有被黑客篡改,有没有发生冲突,它会继续把帧头提取出来做一个MD5校验,
然后拿我自己算出来的MD5值和对端交换机发送过来的报文中的MD5值对比,如果结果一样,则这个报文是正常的,
如果结果不一样,那么证明这个报文要么不是被黑客篡改,要么就是一个冲突碎片,交换机会把该报文直接丢弃,FCS是对帧头做校验的
对于公有协议:802.3
它和Etheret2没有太大区别:
Preamble:导前码,在802.3中被分为两个部分,前面7个字节为一部分,剩下1个字节为第二部分
前面7个字节依然叫做导前码,后面1个字节称之为帧起始定界符,帧起始定界符,主要用于区分这个帧是802.3的还是Ethernet2的,它也可以理解为是一个导前码
Length:长度,在802.3中变更为2个字节的type(类型),它用来唯一的标识该数据帧的三层所使用的封装协议(类似于4层的端口,它用来标识7层所使用的协议)
type值为0x0800表示ipv4,type值为0x86DD表示ipv6,相当于交换机不需要查阅3层报头一样知道3层使用的是什么协议
研究网络层报头
在网络层中:IPV4也可以进行数据切片,也只有ipv4可以进行数据切片,ipv6不可以
三层报头:
ipv4:报头最短是20个字节,由于有可选项和填充项,因此ipv4报头长度是可变的,范围是20byte-60byte不等
Ver(版本):描述协议的版本
IHL(报头长度):报头长度,反应整个数据包头的长度
Type of Service(简称TOS):用来实现QoS(服务质量),和标识数据帧的类型
Packet Length(报文长度):包含3层报头在内的整个数据包的长度,如果想知道该数据包所封装的四层数据段长度就用(Packet Length) - IHL = 四层数据段长度
identification(标识符):标识符,用于ipv4在三层帮助我们进一步的切分数据来满足MTU标准,它会给一个数据包每个分片都打上相同的标识符,这样能让中间系统在重组数据分片时知道这是哪个数据包的分片.
Flag(标记):标记,用于ipv4在三层帮助我们进一步的切分数据来满足MTU标准,Flag占3bit,其中最左边的是保留的永远为0,然后一次是DF位,MF位,DF如果为1,就代表这个三层数据包是不允许切片的,如果为0则代表可以切片,
MF表示这个数据分片是否为最后一个分片,用来判断是否掉包,最后一个数据分片MF就是0
Flag. Offset(分段偏移量):分段偏移量,用于ipv4在三层帮助我们进一步的切分数据来满足MTU标准,它判断每个分片到底处于哪个位置
Time to Live(TTL):存活时间,TTL描述的就是一个IP报文在Internet环境中到底能够传多少跳(什么是跳?一台三层网络设备对于Internet而言就是一跳,简单说经过一台三层设备就是一跳),
它用来当网络出现问题的时候,防止数据包按照错误的网络路径在网络中永远不停的传输下去,这个行为称为路由选择环路.一个路由器产生的TTL值一般都是255,
一个三层网络设备在收到一个数据帧之后,会利用分组改写引擎拆掉帧头帧尾,对IPV4数据包,包头做一个处理,它会将TTL值-1之后在发送,也就是说数据帧跨越一台三层设备TTL值就会-1,当一台三层设备收到TTL为0的数据帧时会直接丢弃,这么做可以解决网络风暴
Protocol(上层协议):用于唯一的标识数据帧的传输层(4层)封装的是什么协议
Header Checksum(报头校验和):将ipv4报头中的每个字段都提取出来使用MD5做一个散列计算,得出的值就写在这里,用来对数据包包头做完整性检查的
Source Address:32位的源ip地址
Destination Address:32位的目的ip地址
Options(可选项):可选项,在ipv4环境中有各种各样的基于ipv4的高级应用,当使用这些高级应用的时候,可能ipv4报头包含的字段不够,因此才有了options
Padding(填充项):所有3层报头以及4层报头都需要能够被4个字节整除,如果添加了可选项导致报头长度变长但是又不能被4个字节整除,就填充连续的0或者1,让报头能够被4个字节整除
IPV6:IPV6报头只有40个字节,是定长的
因为IPV6报头是定长的,所以IPV6报头中不存在IHL字段
IPV6报头中也不存在,identification、Flag、Flag Offset字段,这意味着IPV6不支持切片,IPV6基于PMD协议来检查整条路径上的MTU,IPV6在发送真正的报文之前会先试探端到端的通信路径中支持的最小的MTU的网段是哪个,并且MTU对应的值是多少,
只要知道些信息之后,就可以告诉传输层,把分片切到相应的大小,这时候3层就可以避免切片了
IPV6报头中也去除了校验和(Header Checksum)字段,可选项(Options)字段,填充项(Padding)字段,这样做可以保证3层报头比较简介
一个问题:
你作为TCP一个面向连接协议,报头校验和用来实现完整性检测,如果你使用校验和检测出了报文被篡改,你有重传机制嘛,但是对于以太网协议,IPV4协议,IPV6协议,以及UDP协议它们都是无连接协议,你在这些协议里添加报头校验和有没有意义呢?
你计算校验和字段要不要延迟?你检验校验和字段要不要延迟?你检测出报文篡改了有没有重传机制呢?都没有是吧?那现在问题来了,你要校验和有意义吗?
答:
对于TCP这种面向连接的协议,有报头校验和是毫无疑义的,发现了错误可以重传
但是Ethernet、IPV4、IPV6、UDP都不能重传,对于这些不支持重传的无连接协议
除了增加延迟之外还增加了什么?你有没有增加传输可靠性?没有吧,你发现错误也只能丢包嘛?那怎么办呢?
给大家提一个概念:我们之前说过TCP是面向连接的协议,所以可以理解为一组应用程序只要是基于TCP封装,那么这些应用程序发送的流量都是可靠的
那是不是可以理解为一个应用程序基于UDP这种无连接的协议发送的流量都是不可靠的呢?有那么不可靠的应用程序吗?
所以,除了TCP能够提供面向连接之外,很多应用程序本身,它内部也会集成一些可靠机制,也就是说某些应用程序它本身就是面向连接协议,
所以说一般情况如果说一个应用程序没有基于TCP的封装,那这个应用程序多多少少也会集成一些可靠性传输机制。
比如QQ:QQ在四层封装的是UDP,但是有时我们在发送消息时会因为某些原因导致消息发送失败,但是QQ会提醒消息发送失败,是否需要重新发送.
所以对于一些无连接协议,它添加报头校验和也是有它的理由的
Version(版本):描述协议的版本
Traffic Class(TC):它对应IPV4报头中的TOS字段,效果相同
Flow Label:流标签字段(现阶段是一个保留字段),当IPV6真正普及服役之后,可能会有真正官方的定义
Payload Length:它对应IPV4的(Packet Length)字段-IHL字段,它表示去除掉IPV6报头之后的整个四层数据段长度
Next Header:它对应IPV4报头中的Protocol字段
Hop Limit:它对应IPV4报头中的TTL字段
Source Address:128位源IPV6地址
Destination Address:128位目的IPV6地址
研究传输层报头
四层报头:
UDP:
16-bit source port:标识通信的源应用程序
16-bit destination port:标识通信的目的应用程序
16-bit UDP length:连同包头在内的整个数据长度
16-bit UDP checksum:报头校验和
TCP:TCP报头长度是可变的 20byte-60byte
16-bit source port:标识通信的源应用程序
16-bit destination port:标识通信的目的应用程序
32-bit sequence number:防止乱序
32-bit acknowledgment number:防止丢包,以及重传
4-bit header length:反映整个数据报头的长度
resv:保留的
TCP控制位:
ns:
cwr:
ece:
urg:
ack:TCP第二次握手会将它置为1
psh:
rst:强制断开会话的
syn:TCP第一次握手会将它置为1
fin:TCP完成的时候会将它置为1
16-bit window size:用于流量控制
16-bit TCP checksum:用来防止报头被篡改
16-bit urgent pointer:可以理解为信令字段,当网络设备收到带有紧急指针置为1的数据帧时请立即处理
Options:可选项字段
交换机
1).交换机做为一个二层设备,它可以识别一部分控制信息,(MAC)
2).交换机接口支持100MB/1000MB/10000MB带宽.
3).交换机所有接口都支持全双工模式
4).MAC地址用于全球唯一定位一块网卡
5).交换机是独享带宽.
6).交换机识别MAC地址使用CAM(MAC地址表),CAM包含MAC地址和发包接口以及VLAN标识
7).交换机CAM表中默认没有MAC地址,交换机的CAM可以通过静态写入,和动态学习,交换机默认开启了动态MAC地址学习功能
8).MAC地址动态学习的机制:交换机收到一个数据帧,会截获这个帧头中的源MAC地址,再截获接受到数据帧的接口,这种学习方法又称为基于源MAC地址的学习,学习
MAC地址只能够基于源MAC地址学习,自动学习的MAC表项有一个计时器来计时多长时间过期,(Aging Time)老化计时器,默认为300秒,当链接到交换机接口的PC不再发送
数据包,默认300秒后,删除从这个接口学习到的MAC地址表项,如果该接口 Down或链接该接口的网线Down,或者链接该接口的PC Down了,那么交换机会立即删除从该接
口动态学习到的一切MAC地址表项,静态配置的CAM是永久存在与CAM中的.
9).交换机默认会进行报文检查,报文检查的机制:交换机收到一个数据帧会检查这个数据帧是一个常规的数据帧还是一个冲突碎片,这个动作叫做 FCS,交换机在发
送一个数据帧的时候,为了数据帧不被篡改它会把帧头的所有byte做一个MD5的散列计算(hash),得出一个4字节的散列 值,装入到数据包的帧尾,交换机发送的任何报
文都会携带FCS,而交换机在接收到一个报文的时候,为了检测这个数据包有没有被黑客篡改,有没有发 生冲突,它会继续把帧头提取出来做一个MD5校验,然后拿我自
己算出来的MD5值和对端交换机发送过来的报文中的MD5值对比,如果结果一样,则这个报文是正常的,如果结果不一样,那么证明这个报文要么不是被黑客篡改,要么
就是一个冲突碎片,交换机会把该报文直接丢弃.当判定这是一个合法的数据帧的时候,它才会进行放大信号
10).放大信号,他会进行MAC地址表的学习,提取数据帧的源MAC地址和接受数据帧接口,装入CAM,接下来提取帧头的目的MAC地址,查找 我的看表项,看看有没有对应的
发帧表项,如果有,通过该表项的发包接口,把帧发走,如果CAM中没有,交换机会做一个泛洪.
11)IPV4环境的流量类型:
a).单播流量:点对点流量,一个节点发一个节点收
b).组播流量:一对多,一个节点发,多个节点收,组播是非强制性的一对多流量
c).广播流量:一对多,一个节点发,多个节点收,广播是带有强制性的一对多流量,组播和广播地址是不可能被PC的接口所使用的,任何一台链接交换机的节点发送
一个广播或组播流量,所有节点都会收到,由此会产生广播域.
12).广播域,一个广播报文所能影响到的设备的集合,所有连接交换机的接口共处一个广播域
13).交换机接口可以切分冲突域,但无法切分广播域
路由器
1).路由器是一个三层设备
2).路由器的接口带宽一般是10MB/100MB/1000MB/10000MB
3).路由器工作在全双工模式
4).路由器的转发机制:路由器不但能识别源目MAC地址信息,还能够识别源目IP地址信息,并且路由器收到报文的时候会根据一个三层的逻辑路由 表来进行一个网段到网段的通信,网段就是广播域.
5).路由器接口可以切分冲突域和广播域
认识路由器交换机的启动流程
路由器交换机由七大部件组成:
RAM:随机存储器,相当于路由器的内存,存储一些直接让CPU调用的数据,它可读可写,断电后数据会丢失,它里面存储的是运行配置文件,在关机的时候系统默认会将RAM中的配置文件写入到NVRAM中
ROM:只读存储器,只能读取不能修改,不能删除,所有的网络设备都会包含一个ROM,它存储的都是一些比较必要的信息,比如IOS操作系统(IOS残像,IOS阉割版),它主要用来做故障恢复
FLASH:它相当于路由器交换机的硬盘,它里面存放的有路由器的主IOS操作系统
NVRAM:里面存储的数据在断电后不会被删除,主要放置的是配置文件,这种配置文件称之为启动配置文件,NVRAM中还包括配置寄存器,它指明了路由器交换机在启动后如何加载IOS,例如是从网络加载?还是硬盘加载?还是USB
interfaces:广域网接口,局域网接口,以及一些管理接口
CPU:和PC一样,路由器交换机也有CPU
Mother Board:和PC一样路由器交换机也需要主板,只不过在这里称之为背板,一般衡量一台网络设备的性能,背板带宽也是首当考虑的因素
路由器交换机加点之后会经历什么经过:
Perform power-on self-test(POST):加电自检,检查自身各硬件是否正常
Load and run bootstrap code:加载启动代码,简单理解就是配置寄存器
Find the Cisco IOS Software:在FLASH中查找IOS(操作系统)软件,如果在FLASH找不到会退而求其次在网络中查找,如果网络中也查找不到,那么即在ROM中查找
Load the Cisco IOS Software:找到IOS软件后解压缩IOS(操作系统)软件,然后再加载IOS(操作系统)软件
Find the configuration:在NVRAM中查找启动配置你文件,如果找不到配置文件则直接启动
Load the configuration:加载启动配置文件
Run the configured Cisco IOS Software:启动完毕
查找IOS的流程:
1.Checks configuration register:检查配置寄存器
2.Parses configuration for boot system command:解析启动配置文件中的启动系统命令,它指明了我们当前启动希望使用哪个IOS系统(因为FLASH中可能有多个IOS操作系统)
3.Defaults to first file in flash memory:如果没有启动系统命令,那么默认从FLASH加载第一个IOS到内存,如果失败,尝试第二个
4.Attempts to boot from network server:如果上面所有的都失败,则尝试从网络加载,它会使用TFTP协议(简单文件文件传输协议基于UDP69)
5.Boot helper in image:
6.ROM Monitor:如果网络也失败,则从ROM加载,这个行为称之为ROM Monitor
查看配置文件的方法:
show running-config //查看RAM中的配置文件(运行配置文件)
show startup-config //查看NVRAM中的配置文件(启动配置文件)
show version //查看路由器或交换机的物理或逻辑的摘要信息
show flash //查看该网络设备它的flash里面存储的文件
路由器交换机的配置寄存器(Configuration register)
通过 show version 在最下面可以看到Configuration register 的值, 一般缺省值为0x2102
首先配置寄存器的值是16位,4位16进制数,取值不同会直接影响到路由器会优先加载哪个存储器里的操作系统
例如0x 2102
当第一个十六进制数:也就是最左边的2,取值为0的时候,代表开机的时候,不管FLASH中有没有IOS,不管网络中有没有IOS,都不索引它们,而是直接加载ROM中的IOS残像,直接进入ROMMON
如果其值为1的时候,和取值为2的时候一样,都会进入ROMMON
如果其直是2~F中的任意一个,那么先会检查NVRAM中的启动配置文件,看看有没有启动系统命令,如果没有则优先加载FLASH,FLASH失败再网络加载,网络再失败则加载ROM,进入ROMMON
路由器交换机的权限等级
权限等级分为0 ~ 15级
用户模式默认为1级,用户模式能做的操作非常有限,只能做一下show操作
可以通过 show privilege 来查看当前权限级别
在用户模式下通过enable来进入特权模式,该模式级别为15级,特权模式能做该IOS操作系统支持的所有事情,例如 debug ,但是千万不要debug all、debug ip packet detail,容易导致系统死机,可以通过undebug all或no debug all来关闭debug信息
网络设备关机不像PC可以正常关机,网络设备关机只能直接拔电源,这样配置文件是不会自动保存的,需要我们手动保存,手动保存文件的方法有如下几个命令:
copy running-config startup-config //将RAM中的运行配置文件导入NVRAM作为启动配置文件(只有考NA时使用这个命令)
write //工程中和IE都使用这个命令保存配置文件
write memory //思科官方定义的最权威的保存配置方式
在特权模式下无法配置网络设备,如果想要配置网络设备,必须从特权模式执行configure terminal,进入全局配置模式才行
在全局配置模式下,可执行90%以上的对全局影响的配置命令,例如:hostname、ip name-server
当我们敲错命令的时候,网络设备默认会认为我们是在解析一个域名,它会尽量的去帮助我们将域名转换为IP地址,这样我们每敲错一次命令就要等很长时间,可在全局配置模式中执行:no ip domain lookup让他不再解析
默认全局模式下无法进行show,因为show命令是用户模式下的,不过可以利用命令前面加do 来越级执行,例如 do show run
除了以上三个模式外,网络设备还有一个叫做特殊配置模式的模式,一般包括接口配置、子接口配置模式、控制器配置模式、线路配置模式、路由选择配置模式
例如:
R1(config)#line console 0 //进入console 0口的配置
R1(config)#interface serial 0/0/0 //进入接口配置
当我们在对一个接口做配置的时候后可能会被日志信息冲断我们所敲入的命令,这样我们可能会不知道命令写到哪里了,我们可以在console 配置模式或者虚拟终端配置模式:logging synchronous
当我们在登录一个设备,一段时间不做操作的时候,系统默认会将我们断开,有时我们不希望断开,可以在我们可以在console 配置模式或者虚拟终端配置模式:exec-timeout 20 30 //20分30秒,如果设置0 0表示关闭超时计时器,不过千万不要在企业使用,一般在实验时使用
总结:
当配置预配置一台思科网络设备的时候,建议一定配置下面三条命令:
R1(config)#no ip domain lookup
R1(config-line)#logging synchronous
R1(config-line)#exec-timeout 0 0
一些配置命令
用户模式:
R1>enable //进入特权模式
特权模式:
R1#configure terminal //进入全局配置模式
全局配置:
R1(config)#hostname //设置主机名
R1(config)#banner motd //设置banner信息,#回车开始写,写完后按回车,再按#回车
R1(config)#clock set //设置时钟
R1(config)#ip name-server //配置DNS服务器
R1(config)#clock timezone GMT +8 //将时区定义在东8区
R1(config)#end //无论现在处于什么模式,直接回退到特权模式
R1(config)#disable //直接回退到用户模式
R1(config)#Ctrl+z //直接回退到特权模式
R1(config)#exit //逐级回退
特殊配置模式:
接口配置模式:
description 描述 //配置接口描述
shutdown //关闭接口
no shutdown //开启接口
管理IOS镜像
网络设备的文件传递可以利用console线和rj45线,但是由于console线的速度相当慢,所以一般都用rj45线
对于使用rj45线的情况下,一般我们需要PC和网络设备,PC和网络设备需要在同一个网络中
当从网络设备将文件导出到PC的时候,推荐使用Cisco tftp Server这个软件
当从PC将文件导入到网络设备的时候,推荐使用3CD这个软件
1.从网络设备导出到PC:
(1).PC和网络设备需要在同一个网络中
(2).show flash
(3).copy flash: tftp:
2.从PC导入IOS到网络设备
重点:
在导入IOS之前,一定要看该IOS所要求的最低RAM是多少
在导入IOS之前,一定要看FLASH中是否能够放下该IOS,当FLASH空间还有很大的时候,IOS就直接存放进来,不要删除之前的,当升级失败时,可以回退,
当FLASH空间不够时,删掉之前IOS文件之前,一定要将之前的IOS文件导出来做个备份
步骤:
(1).查看FLASH: show flash //确认FLASH大小是否能够放下该IOS
(2).查看RAM: show version //确认RAM大小
(3).copy tftp: flash:
(4).当文件传递前系统会自动提示是否需要删除Flash内的所有文件,建议不要删除,除非Flash空间确实不足
(5).注意,当在传递IOS文件的时候千万不要中断,别重启设备,避免只用xmodem
3.传递NVRAM中的启动配置文件到PC
重点:
(1).PC和路由器都要开启并且联网彼此互通
(2).直接在路由器使用copy start tftp:实现冗余备份
(3).直接在路由器使用copy tftp: start实现灾难恢复
4.传递RAM中的运行配置文件到PC
重点:
(1).PC和路由器都要开启并且联网彼此互通
(2).直接在路由器使用copy run tftp:实现冗余备份
(3).直接在路由器使用copy tftp: run:实现灾难恢复
5.show和debug的区别
show:
收集静态信息
由于是收集静态信息,所以占用资源少
show一般用于收集一些静态信息
debug:
收集动态信息(实时)
由于是收集动态信息,所以占用资源比较高(开销比较大)
debug一般是用于监测某个过程
R1(config)#service timestamps debug datetime msec //debug信息会包含当前系统时间,精确到毫秒
R1#show processes //实时监测CPU占用情况
R1#terminal monitor //默认情况下通过远程网管设备是不会开启日志信息的,通过该命令就可以开启
网管网络设备的方式
1.本地网管(local-login):
什么要求都不需要,只需要一根console线,网络设备开机即可
2.Telnet:
远程网管方式之一:
网络设备是使用什么样的接口来承载网管流量?
答:
承载本地网管流量的接口是线路接口,远程网管一样也是使用线路接口,承载网管会话流量的永远是线路接口
什么叫线路接口?以line开头的,都有哪些呢? console口,aux口,vty口
vty口和console与aux口有本质区别,vty口叫做逻辑接口,什么叫逻辑接口?表面看不到,在路由器后面没有该接口,一般来说最低端的路由器至少有0~4,5个vty接口
vty接口干什么用的?答:每一个vty接口都可以独立的承载一股telnet会话
如何配置telnet?
使用telnet前提条件:
(1).网管设备和被网管设备必须同时接入网络,并且网管设备能够访问被网管设备(也就是说能彼此ping通)
(2).vty接口必须设置密码,在vty接口中配置的密码都称为线下密码
(3).默认情况下vty接口是强制启用了线下密码认证的,也就是说必须设置密码,否则永远认证失败
(4).如何查看接口是否启用线下密码认证? show run //查看line vty 0 n,其中login 代表强制启用线下密码认证
(5).当通过telnet登录后,用户模式到特权模式还需要一个认证,必须在全局模式下enable password
答:
R1(config)#line vty 0 n
R1(config-line)#password cisco
R1(config)#enable password cisco
为了加强telnet安全,利用本地认证数据库认证:
R1(config)#username admin password cisco //这样默认创建的权限等级为1
R1(config)#username admin privilege 15 password cisco //这样创建的权限等级为15
R1(config)#line vty 0 n
R1(config-line)#login local
3.SSH:
远程网管方式之二:
SSH是一种加密传输的远程连接协议,比Telnet安全
如何配置SSH:
(1).网管设备和被网管设备必须同时接入网络,并且网管设备能够访问被网管设备(也就是说能彼此ping通)
R1(config)#username admin password cisco
R1(config)#line vty 0 n
R1(config-line)#login local
R1(config)#ip domain-name cisco.com
R1(config)#crypto key generate rsa //注意:这里会让你指定秘钥长度,ssh版本2至少需要1024,默认是512,也就是512不支持ssh版本2
R1(config)#ip ssh version 2
R1(config)#line vty 0 n
R1(config-line)#transport input ssh //只允许接受SSH协议
删除秘钥的方法:
R1(config)#crypto key zeroize rsa
4.SDM:Security Pevice Manager
SDM是思科开发的,只能用于网管思科的网络设备,它是一个图形化的软件,它的功能"有限",高端的命令SDM无法完成
pc:
安装SDM管理软件并开启即可,安装的前提是安装JAVA runtime
router:
http+telnet方式:
R1(config)#ip http server //将路由器启动成http服务器
R1(config)#ip http authentication local //http流量做本地数据库认证
R1(config)#username admin privilege 15 password cisco //权限必须是15
R1(config)#line vty 0 n
R1(config-line)#login local
https+ssh方式:
R1(config)#ip http secure-server //将路由器启动成https服务器
R1(config)#ip http authentication local //http流量做本地数据库认证
R1(config)#username admin privilege 15 password cisco //权限必须是15
R1(config)#ip domain-name cisco.com
R1(config)#crypto key generate rsa
R1(config)#ip ssh version 2
R1(config)#line vty 0 n
R1(config-line)#login local
R1(config-line)#transport input ssh //只允许接受SSH协议
5.router to router
telnet:
R1#telnet 172.25.100.21
ssh:
R1#ssh -l username [-v version number] 172.25.100.21
小实验.PPPoE协议
如何让路由器称为猫,来实现拨号上网:
R1(config)#bba-group pppoe global
R1(config-bba-group)#virtual-template 1
R1(config)#interface virtual-template 1
R1(config-if)#ip address 100.1.1.1 255.255.255.0
R1(config-if)#encapsulation ppp
R1(config-if)#ppp authentication chap callin
R1(config-if)#peer default ip address pool 1
R1(config)#ip local pool 1 100.1.1.2 100.1.1.100
R1(config)#intferface fastEthernet 0/0
R1(config-if)#pppoe enable
R1(config-if)#pppoe enable group global
R1(config)#username cisco password ccie
路由器作为客户端拨号:
R1(config)#interface f0/0
R1(config-if)#pppoe-client dial-pool-number 1
R1(config-if)#no shutdown
R1(config)#interface dialer 1
R1(config-if)#encapsulation ppp
R1(config-if)#ppp chap hostname cisco
R1(config-if)#ppp chap password ccie
R1(config-if)#dialer-pool 1
R1(config-if)#no shutdown
R1(config-if)#ip address negotiated
R1(config-if)#pppoe enable
R1(config-if)#pppoe enable group global
CDP协议
CDP:Cisco Discovery Protocol,思科发现协议,它是一个私有协议,它是一个数据链路层协议(2层)
它能够在一台思科设备上通过报文的交互直接获悉和它直连的其他思科设备的信息,这些信息包括:
(1).邻居设备的标识符,也就是主机名(注意是以FQDN表示的)
(2).和本设备直连的其它设备的地址信息
(3).邻居设备的哪个接口连接的本地
(4).邻居设备支持什么功能,例如R(支持路由)、S(支持交换)、I(支持组播)
(5).邻居设备的平台,例如c2811、c2960、c3725
(6).本地接口连接邻居的接口信息
默认情况下,思科网络设备都会开启CDP协议,也就是说当你组网完成后,网络设备则会在每一个能发送报文的接口自动周期性的发送CDP报文来获悉邻居网络设备的信息
,这个周期默认是60秒,这个时间我们称之为(hellotime)
当一台思科的路由器或交换机收到一个CDP报文的时候,它会立刻将这个报文存储并提取里面的信息,放入一张表中,这张表称之为CDP邻居表。
一台路由器或交换机收到邻居发过来的CDP报文,会把所有的信息填充到CDP邻居表中,然后来维护邻居信息,管理员可通过show cdp来查看cdp邻居表信息
一个问题?一台设备获悉了一个邻居信息,填充入邻居表中,这个信息要维护多长时间呢?换而言之,这个邻居信息是否永久有效?
答:
不会永久有效,这个周期是180秒,也就是说邻居信息默认只会存储180秒
只要180秒内没有再收到这台邻居设备的cdp报文,就将该表项从CDP表中删除,这个时间我们称之为(holdtime)
一般建议holdtime时间是hellotime的3倍
相关命令:
R1#show cdp interface //查看开启了CDP协议的接口
R1(config)#cdp run //全局开启CDP
R1(config)#no cdp run //全局关闭CDP
R1(config-if)#cdp enable //对于接口开启CDP
R1(config-if)#no cdp enable //对于接口关闭CDP
R1#show cdp neighbors //显示CDP邻居表中的所有邻居的摘要信息(简洁信息)
R1#show cdp neighbors detail //显示CDP邻居表中的所有邻居的详细信息
R1#show cdp entry R3 //显示指定邻居在CDP表中的详细信息
R1#sho cdp traffic //显示运行CDP之后,已经收到的CDP报文以及传输的CDP报文之类的
R1#clear cdp table //清空CDP邻居表
R1(config)#cdp timer 5 //设置CDP报文发送时间为5秒一次
R1(config)#cdp holdtime 15 //设置holdtime时间为15秒
R1(config)#cdp advertise-v2 //启用CDP版本2,默认情况下只要IOS版本在12.1以上都是CDP版本2
R1(config)#no cdp advertise-v2 //某些情况下可以启用CDP版本1
它的用途:
(1).用来发现和一台思科网络设备连接的其他思科网络设备的信息,帮助我们构建一张基于园区网的拓扑
(2).检测设备间链路问题,当链路间3层不通时,如果通过show cdp neighbors还能看到邻居信息,证明问题出在3层,很可能是你配错ip地址导致3层不通
否则,如果不能看到邻居信息,那证明2层或1层物理层的连通性可能出现了问题
VLAN
到此,NA课程已经进入2层的技术环节,二层技术都是运行在二层交换区块之内的
NA课程主要就是围绕园区网架构来学习的,而园区网二层架构就是交换区块,三层架构则是汇聚层到核心层之间的连接
问:什么是园区网?
答:
一组连续的局域网,它们覆盖的范围是一组大楼或一栋大楼所组成的园区
园区网就是由一组交换机连接稍微给力一点的交换机再连接更给力一点的交换机组成一个大范围的网络
简单来说,园区网就是用交换机把楼与楼之间彼此互联
思科官方将园区网定义为三个层次,分为接入层,汇聚层,核心层
接入层:
接入层负责将网络的边缘用户,也就是终端用户能够连接入网,对于接入层设备,端口密度要求比较高,一般情况下会使用二层交换机来连接
为什么不能使用三层交换机?首先,接入层只是负责将PC或服务器连接入网,不需要在上面做什么策略,其次,三层交换机一般会比二层交换机
贵很多,而一个园区网中会有大量的接入交换机,如果都采用三层交换机来做,那开销岂不是非常大?所以这是不能接受的,对于接入层设备
选型原则就是一定要便宜,端口密度一定要大,所以这就是为什么接入层我们一般采用二层交换机的原因
汇聚层:
为了让一栋楼中的所有楼层能够彼此访问,需要把每层楼的交换机连接到一起,这个交换机就是汇聚层交换机,对于汇聚层设备,我们需要
部署安全特性,所以一般我们采用三层交换机,我们把汇聚层通常叫做基于策略连接的层,它主要做两件事,第一件事就是把所有接入层交
换机连接在一起,第二件事就是定义企业的各种各样的网络策略,基本95%以上的策略都是在汇聚层上做的,其中最为重要的就是安全策略
对于这些交换机首先端口密度也要高,并且设备性能要强劲
核心层:
核心层用来把多个大楼或者说多个交换区块连接在一起,交换区块就是接入层设备和汇聚层设备的组合,从而将整个园区网融合在一起
对于园区网而言核心层的压力是最大的,我们可以把核心层交换机之间的连接称为骨干链路,对于这样的交换机,首先光口密度要大,其
次背板带宽一定要够给力,CPU一定要够给力,接口带宽一定要够给力,转发性能一定要够给力,所以对于核心层交换机,建议使用整网最
好的设备,不建议在核心层做任何策略,因为策略会影响性能,而对于核心交换机而言,光转发数据就已经够费力了,再做策略会导致延迟
,所以核心层什么都不要做,光转发就可以了,尽可能的高速转发你能转发的一切报文
对于园区网而言,接入层带宽一搬推荐使用100M电口,接入层到汇聚层之间推荐使用1000M光口,汇聚层到核心层之间推荐使用10000M光纤
问:
想要组成一个园区网能不能直接拿路由器连PC?
答:
当然不能,一个园区内有多少台PC?,而一台路由器有几个以太网接口?
园区网的目的就是让园区网范围内的所有PC能够上网,所以对网络设备的端口密度要求比较大,所以能符合要求的设备自然而然就是交换机
举个例子:
当我们利用交换机将一层楼的所有PC互联之后,组成了一个什么样的网络?能上网了吗?,答案是不能,只能让该层楼的所有PC互通而已(我们把这称为接入层,交换机又称为接入交换机)
如果我们想要让所有楼层的PC都互通该怎么办?我们可以将每层楼的交换机连接到一个性能更强的交换机上,这样又组成了一个什么样的网络?能上网了吗?
答案是不能,只是能让这栋楼的PC彼此互联了而已(我们把这称为汇聚层,交换机又称为汇聚交换机),如果我们想要和其他楼的PC互通该怎么办?我们可以将每栋楼的汇聚交换机连接
到一台性能更强的交换机上,这又组成了一个什么样的网络?可以上网了吗?答案是不能,这只是让每栋楼的PC互相能够通信了而已(我们把这称之为核心层,交换机称之为核心交换机)
那我们想要所有PC都能够上网该怎么办?我们可以将核心交换机连接到一台路由器(在这里我们称这台路由器为出口路由器), 再通过这台路由器连接到运营商网络
,这样整个园区内的所有PC就都可以上网了,通常园区网内核心交换机的负载是最大的。
再来一个问题:为什么上面的例子中,核心交换机连接运营商网络要用出口路由器?为什么不直接用交换机连接到运营商网络?
答:
因为交换机通常都是以太网接口(说白了就是双绞线),而以太网接口在传输数据时会根据传输距离信号会衰减,一般以太网接口最大传输距离是100米,
而园区网和园区网或者运营商网络彼此互联,肯定不止100米,所以交换机无法满足出口要求,所以这就是出口使用路由器的道理,在整个Internet环境
中支持长距离传输的设备只有路由器,路由器支持串行线缆,而串行线缆的最大传输距离可以很远,长可以长到几十公里,足够园区网彼此连接在一起
还是一个问题:假定一个市有1000个园区网,我们需要将1000个园区网彼此互联该采用什么方式?
方案A:通过路由器彼此互联
方案B:将1000个园区网连接到一个更大的园区网,通过这个更大的园区将小的园区的数据做一个转发,实现彼此互联
答案是B,为什么?
因为一台路由器能够连接广域网线缆的接口非常有限,如果一台路由器只有2个广域网接口,那么1000个园区想要彼此互联,每个园区网至少需要500台出口路由器,
这样明显是不现实的,所以我们采用方案B是最好的办法,方案B就是所有低级的园区网使用路由器使用广域网线缆连接到一个比较高端的园区网,
而这个园区网就是我们的ISP:Internet Service Provider(互联网服务提供商)也就是我们俗称的运营商网络,中国最大的运营商无非电信和网通
园区网的接入层和汇聚层可以理解为交换区块(二层环境),汇聚层到核心层之间称之为三层环境
VLAN:
什么是LAN?LAN就是一个局域网,一个局域网就是一个网段,网段由路由器的三层物理接口来分割,路由器的一个接口分割一个广播域
在一个典型的园区网环境中,所有交换机同处一个广播域,广播域较大时,所有PC收到广播报文的几率也就越大,大量的广播或组播报文会极大的浪费网络设备的CPU和带宽,增大网络开销
而解决办法只能是将整个大的广播域分割成为一个个小的广播域,但是只有路由器能够分割广播域,而路由器的开销较大,而且接口较少,所以使用路由器来解决该问题是不现实的
那我们能不能使用交换机来分割广播域呢?答案是,当然可以,这就需要用到我们的VLAN技术
什么是VLAN:VLAN就是一个虚拟局域网(它是一个纯二层的概念),它只能在交换机上部署
VLAN能实现什么呢?能够实现让交换机的二层接口,在二层,逻辑的划分广播域,我们可以说一个VLAN就是一个广播域
在我们思科的交换机上VLAN可划分的范围是1~4094,其中1、1002~1005这几个VLAN是保留的,我们不能对它们做任何配置包括创建和删除
VLAN的配置我们无法通过show run 或 show start 来看到,因为VLAN的信息是存储在FLASH中的VLAN.dat中,这是一个单独的文件,类似运行配置文件和启动配置文件
默认情况下交换机的所有接口都处于VLAN1中
VLAN是纯二层的协议,当交换机之间是二层连接的时候,不同交换机的相同VLAN号中的主机同属一个广播域,但是当交换机之间的连接被三层连接阻断的时候,不同交换机中的相同VLAN不在属同一个广播域
所以建议部署VLAN在纯二层网络的环境下部署,一个VLAN最好只存在于一个交换区块中,这种部署方式我们称之为本地化VLAN部署
VLAN-1:
VLAN1叫做缺省VLAN,又叫管理VLAN,又叫做本征VLAN.
缺省VLAN:一个交换机默认情况下如果不做任何VLAN配置,那么该交换机的所有接口默认都属于VLAN1
管理VLAN:交换机的接口都是二层接口,无法配置ip地址,那么我们想要远程Telnet管理它该怎么办?答:交换机的VLAN1可以启一个逻辑三层接口,可以在该接口配置ip,这个接口我们称之为SVI(Switch VLAN Interface)
,一个交换机只有VLAN1的SVI可以配置ip地址,其他VLAN的SVI不可以配置IP地址,所以我们把VLAN又叫做管理VLAN
本征VLAN:解释见下方Trunk中继链路
VLAN1002~1005:
当我们使用非Ethernet(以太网)协议的时候,可以使用这些VLAN,来为这些协议提供服务,这4个VLAN不能用于以太网环境
VLAN分类:
1~1005:常规VLAN,对于企业网络通常部署常规VLAN就可以了,一个二层交换机通常只能部署常规VLAN
1006~4094:扩展VLAN,一般用于运营商网络,三层交换机既可以部署常规VLAN又可以部署扩展VLAN
VLAN在二层划分广播域的原理:
其实就是基于交换机的CAM(看表),一个看表项会包含3个元素,MAC、发包接口、VLAN标识,交换机地址学习就是通过接受一个数据帧并查看帧头中的源MAC地址
,来做看表的学习,这个接口既然一定要和一个VLAN关联,那通过这个接口收到的帧,学到的MAC地址也要和这个VLAN关联,而交换机收到一个组播或广播流量会泛洪
,这个泛洪和集线器的泛洪是截然不同的,交换机的泛洪称为基于VLAN的泛洪或者叫做VLAN内泛洪,因为交换机收到一个帧,只会查看和这个帧VLAN相关的看表项
,所以如果交换机把一组接口划入一个相同的VLAN,那么所谓的泛洪只会泛洪给该VLAN内的所有其他成员,这就是VLAN划分广播域的原理
VLAN的配置:
SW1#show vlan brief //查看VLAN信息
三种创建VLAN的模式:
1.vlan database //这种模式不支持创建扩展VLAN
SW1#vlan database //这是一种比较古老的VLAN配置模式
SW1(vlan)#vlan 100 //创建VLAN100
SW1(vlan)#apply //将VLAN缓存立即写入VLAN.dat
SW1(vlan)#vlan 200 name IT //创建VLAN200并取名为IT
SW1(vlan)#exit //它和apply都可以让创建的VLAN生效,不过它还会退出VLAN database模式
SW1(vlan)#no vlan 100 //删除VLAN 100
2.全局模式下直接输入vlan vlanID
SW1(config)#vlan 100 //创建VLAN100
SW1(config-vlan)#name IT //改名该VLAN为IT
SW1(config-vlan)#exit //exit后VLAN才会生效
SW1(config)#vtp mode transparent //设置该交换机的VTP模式为透明模式
SW1(config)#vlan 2000 //该模式可以创建扩展VLAN,该交换机必须是3层交换机,该交换机的VTP模式必须是透明模式
SW1(config-vlan)#name seiya
SW1(config-vlan)#exit
SW1(config)#vlan 100
SW1(config-vlan)#shutdown //将VLAN100的模式设置为shutdown,一个VLAN被shutdown后,这个接口的所有成员不能收发任何流量
SW1(config)#no vlan 100 //删除VLAN100
SW1(config)#no vlan 200 //删除VLAN200
SW1(config)#no vlan 2000 //删除VLAN2000
3.CCIE考试可能会用到,利用宏创建
SW1(config)#macro name VLAN //定义一个宏,名字为VLAN
Enter macro commands one per line. End with the character '@'.
vlan 100
name IT
vlan 200
name flash
vlan 300
name bisu
exit //exit一定要加,否则容易vlan300添加不成功
@ //@键回车结束
SW1#show parser macro name VLAN //查看名字为VLAN的宏的信息
SW1(config)#macro global apply VLAN //应用该宏
SW1(config)#no macro name VLAN //删除名为VLAN的宏
将接口与vlan关联
SW1(config)#interface e0/0
SW1(config-if)#switchport mode access //将接口定义为接入模式
SW1(config-if)#switchport access vlan 100 //switchport表示二层以太网接口,将接口e0/0划入vlan100
SW1(config)#interface range ethernet 0/2 - 3 //批量划分vlan,将e0/2 ~ 3划入vlan100,这种方法只能用于连续的接口
SW1(config-if-range)#switchport mode access //将接口定义为接入模式
SW1(config-if-range)#switchport access vlan 100
SW1(config)#interface range ethernet 0/0 , ethernet 0/3 , ethernet 0/1 //划分不连续的接口,通过空格","空格来分割
SW1(config-if-range)#switchport mode access //将接口定义为接入模式
SW1(config-if-range)#switchport access vlan 100
SW1(config)#interface range ethernet 0/0 , ethernet 0/1 , ethernet 0/2 - 3 //混合使用的情况
SW1(config-if-range)#switchport mode access //将接口定义为接入模式
SW1(config-if-range)#switchport access vlan 100
VLAN中的Trunk中继链路:
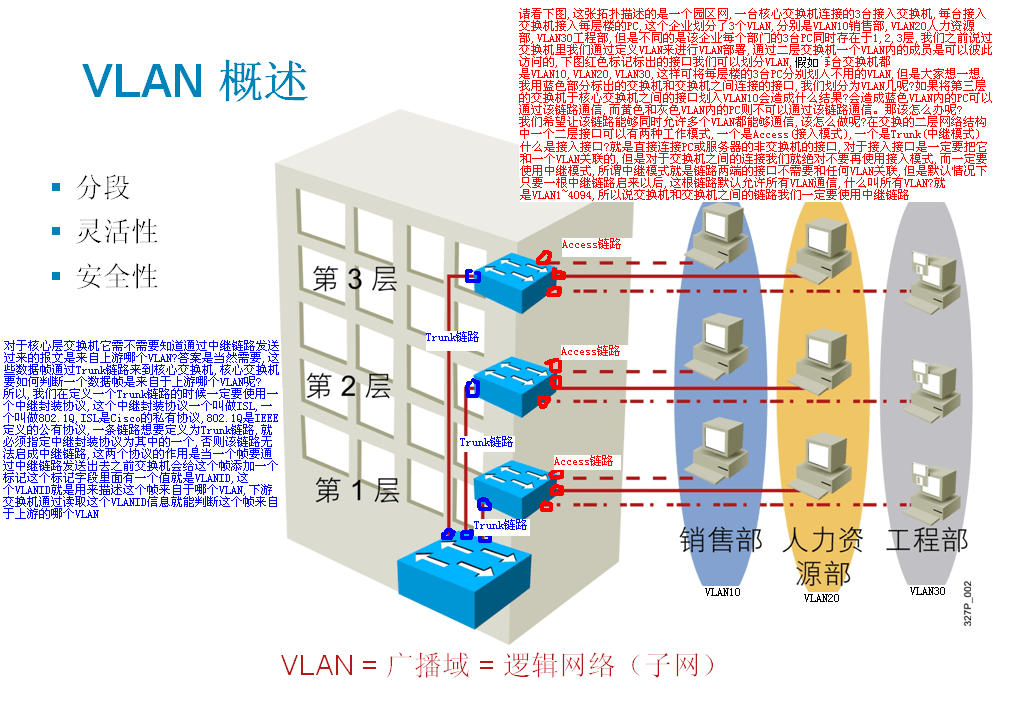
关于本征VLAN:
在802.1Q中定义的一种VLAN叫做Native VLAN,本征VLAN,它是什么概念呢?任何一个VLAN的帧到达中继链路之前,交换机一定要给他打一个标记,用来标识该帧是来自与哪个VLAN,但是默认情况
,当中继链路使用802.1Q封装的时候,会定义一个本征VLAN,这个VLAN的帧到达中继链路之前是不用打标的,一般情况下我们会把流量最大的VLAN定义为本征VLAN
,这样的好处是节省交换机的开销,因为打标是要消耗CPU资源的,而且802.1Q中标记是打入帧头中的,这样就打乱了帧头的格式,FCS校验和就会重新计算
,所以我们把流量最大的VLAN定义为本征VLAN后,它们就不需要打标了,这样就节省了开销,让用户体验变的更好,如果没有定义本征VLAN,默认情况下就是VLAN1
,本征VLAN是基于Trunk链路,而不是全局,例如,一条Trunk链路的本征VLAN是1,而另一条Trunk链路的本征VLAN是2,互相是不影响的
定义Trunk接口的方法:
SW1(config)#interface ethernet 0/3
SW1(config-if)#switchport trunk encapsulation dot1q //定义中继封装类型为802.1Q
SW1(config-if)#switchport mode trunk //将接口启用为中继接口
SW1#show interfaces ethernet 0/3 switchport //查看接口模式信息
SW1#show interfaces trunk //查看中继相关的信息
VTP协议
首先先看一个问题,当我们企业中一个交换区块有很多交换机,例如7台,而我们又划分了2000个VLAN,要实现VLAN间通信,有
个前提条件是,每台交换机都必须拥有相同的VLAN吧?好,那你一台一台的配置VLAN需要多久?比如创建一个VLAN要2条命令,
2000个VLAN就是4000条命令,*7 = 28000条命令?你觉得你需要用多久?
好,VTP协议就是用来解决这个问题的:
VTP协议的作用就是当我们在一组交换机上同时启用VTP,就能够彼此通过交互VTP报文,实现VLAN.dat信息中的VLAN信息同步
注意:VTP协议不能乱部署,VTP协议必须要基于一个域的概念来部署,什么是域?就是一组使用中继链路互联的交换机拥有相同
VTP域名的时候,我们称这组交换机组成了同一个VTP域
思科的交换机默认VTP协议是开启的,你想关也关不了,但是一台交换机默认情况下它的VTP域名是空的,就是没有VTP域名
在大家的域名都为空的时候,这时候VTP不算是同一个VTP域,基于这一点关于VTP一个高级的特性,这个特性就是VTP的洗刷
过程,什么叫VTP域名洗刷?假定一组交换机使用中继链路彼此互联,默认假定大家的VTP的配置都是初始值,也就是大家的VTP
域名都为空,那这时候当我们在一台交换机创建一个VTP域名的时候,会导致所有和我使用中继链路互联的交换机能够自动
同步我的域名,它们也会同时把域名改成你设置的域名,这个VTP洗刷有个条件就是大家的VTP域名初始都为空域名的情况
才会触发VTP域名洗刷
VTP所定义的报文我们称之为VTP通告报文以及叫做VTP请求报文,所有VTP通告报文是一定要在中继链路上传输的,所以说
单纯的二层连接是不足以运行VTP的,想要运行VTP你一定要使用中继
在一组VTP域中,一台交换机能够扮演什么角色?
一个叫做Server(服务器):创建VLAN,修改VLAN,删除VLAN,发送和转发通告,同步,Server模式只能创建常规VLAN
一个叫做Client(客户端):无法创建或删除VLAN,发送和转发通告(极端情况下,这可以理解为一种设计失误),同步
一个叫做transparent(透明):仅创建本地VLAN,仅修改本地VLAN,仅删除本地VLAN,转发通告,不进行同步,可以创建常规VLAN,也可以创建扩展VLAN
一台启用VTP的交换机一定只能扮演其中的一种角色,默认情况下VTP的角色是Server,一个VTP域内是必须要有一个Server的,但是Server未必只有一台
汇聚层交换机建议设置成Server模式,接入层交换机建议设置为Client
VTP信息和VLAN信息一样,不会保存在配置文件中,它是保存在VLAN.dat中的
VTP的运行:
VTP一共有三种报文,一种汇总通告,一种叫做子集通告,它们大体的作用就是:通过在通告报文中携带所创建的VLAN信息,让其他的邻居交换机收到通告报文之后去同步"我"所拥有的VLAN
通告报文有两中发送方法,一个是周期性发送(默认每300秒一次),一个是触发更新,当Server交换机VLAN发生变化的时候,就会把发生变化的信息去同步给其他交换机
通告报文中会包含一个参数叫做配置修订号(用来描述VTP报文新旧的数值),这个值对于一台交换机而言,如果你默认没有做过VLAN相关的配置,这个值它是0,它代表这台交换机的VLAN.dat
没有做过任何的改变,当你VLAN信息发生改变后这个值会发生改变,VLAN信息发生过改变,这个值就是几,这个值越高,代表所拥有的VLAN信息越新,反之代表所拥有的VLAN信息越陈旧
注意:在一个域内,当"我"通过"我"所连接的Server模式的交换机收到一个VTP通告之后,在"我"学习里面的VLAN信息之前,"我"会先比较VTP通告报文中的配置修订号的值和"我"本地
的配置修订号的值谁更高,如果"我"收到的更高,代表我接收到的VLAN信息更新,那这时候"我"就会更新"我"自己的VLAN信息,并且帮助Server把这个报文泛洪发送给"我"其他的邻居
如果我的配置修订号和Server的一样,对于这种报文"我"会直接丢弃,如果"我"的配置修订号比"你"的高,"我"会将"你"给我发的VTP报文丢弃,但是"我"会给"你"发送VTP通告,来让"你"
学习我的VLAN信息,因为"我"的VLAN信息比"你"的更新,这种行为称之为反向通告
对于反向通告,我们一定要避免一种情况,例如在一个VTP域中,管理员已经创建好VLAN和VTP,但是后期,需要再加入一台接入交换机进来,让更多的PC连接入网,这时候你一定要检查
这台新加入的交换机它的配置修订号,一定要小于你现存的VTP域中的交换机的配置修订号,避免新交换机将VTP信息通告给现存的域中的交换机
如何将交换机的配置修订号降低?不可能降低的,只能清为0,那如何清为0呢?答两种方式:
SW1(config)#vtp mode transparent //改变成透明模式会清为0
SW1(config)#vtp domain cisco.com //修改VTP域名,也会清为0
在3550交换机上当配置修订号为0的时候,会出现一个BUG,那就是它不管处在什么模式,只要配置修订号为0,那么它将不会在接受和发送任何VTP报文
所以为了避免这种问题,我们建议让VTP报文>0即可,怎么操作呢?
SW1(config)#vtp mode transparent
SW1(config)#vtp mode server
SW1(config)#vlan 100
SW1(config)#no vlan 100
VTP的修剪:建议启用
在研究VTP修剪之前,先分析一个问题,之前说过交换机在收到一个组播或广播流量的时候,它会进行基于VLAN的泛洪(如果这个帧在cam表中并没有对应的mac地址表项能够转发它,它就会将该帧泛洪给该VLAN内的所有其他接口
请注意,这所有接口中是否会包含中继接口?答案是,会,因为中继链路它允许所有VLAN通行,所以即便你在交换机上部署
了VLAN,VLAN中的成员不停的发送广播,这个广播流量其实是可以发给域内的所有交换机的,因为交换机是通过中继链路
互联的,所以说只要交换机之间端到端之间都是通过中继链路互联的,那这时候任何VLAN内的PC它所发送的广播或组播
流量事实上会影响到整网的交换机,这样做对于带宽结余,以及对于交换机的CPU利用率都是比较低的,效率是比较低的
为了优化这个问题,我们就要启用VTP修剪,它就是用来限制一台交换机到底应不应该把泛洪流量通过中继链路发走
什么时候应该发送泛洪呢?当收到一个VLAN的广播流量的时候,先判断"我"的中继链路对端的交换机上有没有该VLAN的成员接口存在
如果说邻居交换机压根就没有一个接口属于该VLAN,这时候"我"就不会将该广播流量泛洪给"你"
部署交换技术的正确顺序:
Trunk --> VTP ---> VLAN ---> config access
配置VTP相关的命令:
SW1#show vtp status //查看VTP状态
SW1(config)#vtp domain cisco.com //设置VTP域名
SW1(config)#vtp mode ? //设置VTP模式
SW1(config)#vtp version ? //设置VTP版本,一般建议使用版本2
SW2(config)#vtp password cisco //设置VTP密码为cisco,如果要设置密码,必须在所有VTP交换机上启用相同的密码
SW2#show vtp password //查看VTP密码
SW2(config)#vtp pruning //开启VTP修剪,Server模式或透明模式才能开
SW2(config-if)#switchport trunk allowed vlan ? //设置该中继链路允许通行的VLAN
小实验.怎样网管交换机
假定两台二层交换机,SW1、SW2
SW1的23、24端口连接SW2的23、24端口
我们怎样让SW1 Telnet SW2?
SW1(config)#interface vlan 1
SW1(config-if)#ip address 12.1.1.1 255.255.255.0 //还记得这个把,我们在前面说过,这个叫SVI
SW1(config-if)#no shutdown
SW2(config)#interface vlan 1
SW2(config-if)#ip address 12.1.1.2 255.255.255.0 //还记得这个把,我们在前面说过,这个叫SVI
SW2(config-if)#no shutdown
SW2(config)#line vty 0 4
SW2(config-line)#password cisco
SW2(config)#enable password cisco
SW1#telnet 12.1.1.2
STP协议
在研究生成树协议之前,我们先分析一个问题,路由器之间会不会出现路由环路?一般是不会的吧?我们的路由器除了直连的路由它能够自动获悉之外
,任何非直连路由一样可以通过要么静态路由,要么动态路由选择协议,让路由器知晓了去往一个目的的报文怎么走,那么你觉得这个路由出现环路的
记录大吗?基本是不会的对吧?因此,引出一个问题,在路由环境中,我们能不能拥有路径冗余,可不可以一个路由器去往一个目的地可以允许有多条路径
存在?答案是可以的,因为路由器有一个等价负载均衡的概念,就是当一台路由器发现有多条路径都可以去往一个目的的时候,而这多条路径如果它们
对应的度量值一样,那这个时候路由器可以把这个路由条目信息写入路由表当中,并且这个行为不会造成任何环路,也就是说路由器是支持冗余的
简单说就是路由器之间可以连2根线,这种连接就叫做冗余连接,这样可以解决单点故障,什么叫单点故障,就是非冗余连接所造成的故障
那么问题来了,我们的交换机能不能使用冗余连接?
我们假定有2台交换机SW1和SW2,它们都接入了一个PC,假定SW1接入的PC名字为A,SW2接入的PC名字为B,它们都属于VLAN10,这两台交换机之间通过2跟线进行冗余连接
,这2根链路都是中继链路,并且中继链路是放行VLAN10通行的,如果此时A向B发送组播或广播流量会造成什么样的结果发生?首先会导致SW1泛洪,它会把
这股流量通过VLAN10内的所有其他接口发走,并且它会把流量通过中继链路发送出去,这个环境中不管是否启用VTP修剪,这个泛洪都会从中继链路被发送,因为
SW2身后也有连接VLAN10成员,这个时候SW1会将这股流量拷贝成2份通过中继链路发送下去,接下来SW2收到这股流量后(因为这股流量是广播流量),SW2
也会进行泛洪,它会将通过这两根链路收到的流量同时泛洪给B,并且左边链路收到的流量它会通过右边的链路泛洪出去,通过右边路径收到的流量它会通过
左边链路泛洪出去,这时候什么情况发生了?这股广播流量是不是又回到SW1了?那么SW1会怎么做?是不是还会继续将该广播流量泛洪出去?这就形成了一个
环路,我们将该行为称之为广播风暴,造成广播风暴的原因就是交换环路,那是什么造成了该问题呢?就是SW1和SW2之间的冗余连接,如果这时候我帮你把其中
一根链路切断呢?这时候由于SW1和SW2之间只剩1根链路了,这时候如果A再发送组播或广播流量,SW1就只能从这一根链路泛洪,那么当SW2收到这股流量的时候
它会将该流量泛洪给除了该接口以外的其他接口,这时候SW2把流量泛洪给B之后,就没有了其他可泛洪接口,所以就不会出现广播风暴的问题了,那么记住一点
我们在设计交换网络的时候,交换机之间一定只要1根链路连接即可,这样就不会出现广播风暴的问题,但是如果这样设计,就会出现另一个问题,那就是网络的
健壮性无法得到保障,容易出现单点故障,当这根链路down的时候,岂不是GG了?所以,我们能不能既能解决单点故障问题,又能避免广播风暴问题呢?答案是,能
就是运行我们的STP生成树协议.
STP生成树协议:
在带有冗余的二层环境中通过运行生成树协议,它会以树形结构算法,来做一个计算,计算完毕后它能判断出网络中哪条路径最优,然后其他的路径它会临时
帮你阻塞掉,让你在整个交换环境中只留这一条路径,能够保证当生成树完成计算之后,这条路径只要一旦确定好之后,当完成收敛,任意两个节点之间有且只
有一条可行路径,把所有那些不优的冗余路径统一都给阻塞掉,当然这个阻塞是逻辑的,当最优路径不可用的时候,能够立即将阻塞的冗余路径重新开启,这时候
两个节点间还是有且只有一条可行路径,这时候我们就不用担心广播风暴的产生了,并且网络的冗余性,网络的健壮性还能够保存,这就是生成树协议所干的事情
简单说生成树协议帮助我们把这些能够造成交换环路的路径给临时的阻塞掉,任何的网络环境中,只要你有交换机存在,这个交换机就一定要运行生成树协议,
生成树协议不是思科私有的,它有三个版本都是由IEEE组织定义的,分别是IEEE802.1D-STP、IEEE802.1W-RSTP、IEEE802.1S-SMTP
生成树协议有什么概念?
(1).它是一个公有协议
(2).它有三个版本:
802.1D STP
802.1W RSTP
802.1S MSTP MST MIST
生成树的作用是:
把带有冗余的二层环境中通过逻辑阻塞一些冗余路径来实现让这个拓扑形成一个逻辑的树形结构,从而避免广播风暴的发生
那么它是怎么阻塞的?或者说通过什么方式来阻塞冗余路径的?
通过三个层面的选举实现的:
(1).第一个层面就是在一个生成树域内唯一的选举一台根桥,什么是生成树域?答:对于802.1D而言就是使用中继链路互联的一组运行相同版本的生成树协议的交换机
(2).第二个层面就是在所有的非根桥上选举一个根端口(Root Port),简称RP,每台非根桥有且只有一个RP,这个RP可以理解为非根桥去往根桥路径最短的接口
(3).第三个层面就是在交换机之间的链路两端选举一个指定端口,根端口的对端一定就是指定端口(简称为DP),RP的对端一定是DP,而DP的对端可能是RP可能是NDP(非指定端口)
第一个层面的选举--怎么选举根桥的?
生成树协议在交换机之间会发送一个BPDU报文(Bridge Protocol Data Unit),BPDU报文默认2秒发送一次,其中有一个非常给力的字段叫做Bridge ID,还有一个字段叫做Root ID
(1).Bridge ID字段一共有8个字节,它分成两段,第一段2个字节,描述的是该交换机的优先级,取值范围是0~65535,缺省值是32768,比较的时候是该值越小优先级越高,这个值是可以修改的,修改之后的值必须要能够被4096整除
,第二段6个字节,描述的是该交换机的背板MAC地址,注意,当一台交换机启用了生成树协议之后,它一定会对应一个域内唯一的Bridge ID,也就是说在一个生成树域内Bridge ID是唯一的
,这个Bridge ID就是由优先级和背板的最小MAC地址组合而成,由于MAC地址全球唯一,所以我们可以理解为BID,不但域内唯一,甚至全球唯一
(2).Root ID,RID指明了一个生成树域内的根交换机的Bridge ID
当我们组成一个生成树域的时候,域内的所有交换机首先都会非常大胆的认为自己就是根桥,它们都会向域内的所有成员发送BPDU报文,由于它们都认为自己是根桥,所以发送的BPDU报文中的BID和RID字段都是自己
,这个BPDU是以组播形式发送的,所以交换机在收到这个报文的时候会基于中继链路范洪,收到后不但会检查里面的信息还会将这个报文拷贝若干份发送给其他交换机,所以,当第一轮BPDU报文交互完成后
,每台交换机都能获悉所有其他交换机BPDU,这时候交换机会拿自己的BID和其他交换机的BID字段进行比较,谁的BID值最小,谁就是根桥,在比较的时候,先比优先级字段,如果优先级相同,再比MAC地址字段
,当根桥选举完成后,就只有根交换机能继续发送BPDU报文,并且这个报文的发送周期是每2秒一次,非根交换机无法再发送,这就是STP选举根桥的方式.
第二个层面的选举--怎么选举RP的?
(1).Cost of path字段,简称CoP,它用来描述一台非根桥的接口去往根桥的路径的好坏(代价),代价越高路径越差,代价越小路径越好,描述一条路径的好坏一般是基于什么信息?
答,基于链路带宽,带宽越高路径越好,带宽越低路径越差,IEEE定义的CoP的值在早期,是基于一个线性的空间,就是用一个固定的值去除以链路的带宽,10M的CoP的值为100
,100M的CoP的值是10,1G的CoP的值是1,10G的CoP的值也是1,这种早期的线性标准非常不好,因为千M和万M的CoP都是1,所以对于现今的网络环境
,IEEE定义了另一种非线性的跟路径计算标准,10M的CoP值是100,100M对应的是19,千M对应的是4,万M对应的是2,当今交换机的CoP计算都是基于新标准计算的
(2).Port ID字段(2个字节),一台交换机启用生成树的接口就是使用Port ID来标记的,这个字段分为两个部分,第一部分1个字节,它表示优先级,取值范围是1~255,缺省值为128
,这个值可以被修改,但是必须要能被16整除,第二个部分描述的是接口的编号,例如f0/0,PortID也是值越小越好,接口编号的比较,对于模块化设备,Fa1/1 > Fa0/24
当根桥选举完成后,根桥会继续发送BPDU报文,报文中携带的CoP默认是0,当其他交换机收到BPDU报文之后,会对CoP字段进行改写,改写无非就是加上一个值,加上的值就是它们之间
的路径的CoP值,到底加多少是取决于接收到这个BPDU报文的接口的带宽,例如"我"的接口是千M,根交换机和我相连的接口是百M,那么"我"收到BPDU报文后,加的值就为4,所以说,
CoP的值只取决于接收接口的带宽,和链路带宽没有关系
那交换机如何选举RP呢?
(1).比较入站方向的路径代价(CoP),交换机会比较所有端口中CoP值,选举最小的为根端口,但是当该交换机有多个接口时,如果两个或多个接口之间的,CoP值相同时,那么它会比较第二个条件
(2).比较发送者的Bridge ID,当交换机接收到一个BPDU报文时,它除了更改CoP的值以外,还会改变Bridge ID的值为自己的Bridge ID,目的就是让下游交换机知道该BPDU由谁发送,由谁转发
(3).比较发送者的PortID,BPDU需要通过接口发送,通过一个接口发送的BPDU包含的PortID就是该接口的PortID,第三步一般不会产生比较,因为前面说过,两台交换机的Bridge ID不可能一样
那什么时候会比较第三步呢?
一个比较二笔的情况,当同一个交换机的两个端口通过线缆互联(自己连自己)。这时候它们的Bridge ID一样,就会用到Port ID
第三个层面的选举--怎么选举指定端口(DP)?
(1).比较出站方向的代价(CoP),就是转发BPDU出站的方向的CoP,CoP小的将被选举成为DP,而这个DP对端,只要不是RP,那么它就被指定为NDP
PS:这时候交换机的端口的所有角色就出现了,一个叫RP,一个叫DP,一个叫NDP,其中RP和DP可以工作在转发状态,什么叫做转发状态?
就是既可以收发BPDU,又可以收发常规数据帧,而NDP只能收发BPDU报文,不能收发常规数据帧,只要一条路径中有一个NDP,就可以理解为
该路径被逻辑的阻塞了
(2).比较发送者的Bridge ID
(3).比较发送者的Port ID,第三步一般不会产生比较,因为前面说过,两台交换机的Bridge ID不可能一样
那什么时候会比较第三步呢?
一个比较二笔的情况,当同一个交换机的两个端口通过线缆互联(自己连自己)。这时候它们的Bridge ID一样,就会用到Port ID
关于DP,由于根桥发送的所有BPDU,默认CoP值出站方向都是0,所以,基本根桥所有的接口都是DP
一个接口在生成树协议中有什么状态?
对应着接口的三种角色,一个接口只能工作在下面四中状态中
Blocking:阻塞,NDP的状态就是Blocking,一个接口,它默认的模式就是Blocking,这个状态只能收发BPDU,不能收发常规数据帧,这个状态是永久的。
Listening:监听,Listening状态下,一样只能收发BPDU,不能收发常规数据帧,这个状态是临时的,默认是15秒,这个计时器是(Forward delay)
Learning:学习,Learning依然只能收发BPDU,不能收发常规数据帧,不同的是,Learning可以启用MAC地址的自动学习,,这个状态也是临时的,默认是15秒,这个计时器是(Forward delay)
交换机的MAC地址学习机制,就需要接口至少在Learning状态以上才能自动学习
Forwarding:转发,RP和DP确定身份之后,它们的状态就是Forwarding,这个状态能收发BPDU,能收发常规数据帧,能进行MAC地址学习,这个状态是永久状态
关于BPDU中的三个计时器
BPDU报文中有三个字段,Max age、hellotime、Forward delay
Max age:
生成树有可能会经历拓扑改变,例如一根链路down了,这时候需要重新收敛,重新收敛需要具备前提条件,条件是要有交换机发现错误产生,在这里注意
,一台交换机通过一个接口收到根桥的BPDU,在收到BPDU的时候,它就会把这份BPDU保存在这个接口的一个缓冲的Buffer里面,目的是为了维持拓扑的稳
定性,BPDU2秒钟发送一次,只要收到它,就把它临时的保存下来,这个记录的时间缺省值就是Max age,也就是20秒钟,如果能够持续不断的2秒一次的收到
根桥发送的BPDU,代表到达根桥的路径还在,代表这个接口还具备到达根桥的连通性,原因是只要收到一个BPDU,就会把这个BPDU缓存的计,时器重置为20秒
,当然如果20秒都没有收到BPDU报文,那代表接口可能失去到达根桥的连通性,那对于这个接口就需要重新进行生成树计算了.
在这里需要注意,生成树所经历的拓扑变更无非也就是3类:
(1).第一类称之为严重拓扑变更,例如交换机接口烧掉,链路被剪断,这会导致交换机连接该线缆的接口能直接发现这一点,对于这种情况,会立即进行重收敛,不需要等待Max age的时间来发现拓扑变更
(2).第二类称之为间接性拓扑变更,讲简单点就是链路down了,但是这个down的行为不会影响交换机的接口,这个时候交换机发现不了链路down了,这时候就必须要通过Max age的时间来判定能不能到达根桥了
,如果判定连通失败,就发现了拓扑变更错误,这时候才会进行拓扑的重收敛
(3).第三类称之为细微性拓扑变更,一台交换机连接一台PC,PC连交换机是为了收发报文(也就是上网),默认情况下,接口是Blocking状态,如果一台PC
连接到交换机上,从线缆连接完成这一时刻开始,到能够上网需要多长时间?答案是30秒,因为从Blocking到Forwarding需要经历30秒,当PC不上网
关机时,会导致交换机接口检测到这根链路down了,这时候也会告知拓扑变更,从而进行重收敛,但这个收敛有没有必要?答案是,没有必要,那该怎么办?
在这里需要注意,BPDU报文,并不是802.1D定义的唯一一种报文,除了这种报文之外,还有一种报文叫做TCN-BPDU(topology change notice-BPDU)
这种BPDU称之为拓扑变更通知BPDU,这种BPDU所有交换机都有资格去发,什么时候发呢?就是当检测到拓扑发生改变的时候,这个报文发给谁呢?
就是发送给根桥,根桥收到TCN-BPDU后,根桥会立即触发一个TC置位的配置BPDU(TC-BPDU拓扑变更位置位的BPDU),这个BPDU第一步会发给域内的
,所有交换机告知它们拓扑发生了改变,请立即重新收敛,第二步还会叫接收到该BPDU的交换机将它们CAM看表中的老化计时器从默认的300秒,
更改为Forward delay的值,缺省是15秒,什么叫老化计时器?交换机学习到的MAC地址不会永久的保存在CAM表中,老化计时器就是它的超时时间
,这样做的好处是,当拓扑发生变更的时候,尽可能的让你把老的CAM表项中关联的与MAC地址对应的发包接口项删除,好学习新的发包接口项,以
适应新的拓扑结构.避免发生交换黑洞,什么是交换黑洞?就是一个交换机看表中所关联的发包接口,已经down掉,但是交换机还是从该接口发送
数据帧,这个行为就称为交换黑洞.
hellotime,描述的是根桥发送BPDU的周期,默认是2秒
Forward delay,描述的是Listening,Learning模式维持的时间,默认是15秒
注意:
关于这3个计时器,也给我们描述了一个官方定义的缺省的运行802.1D的生成树域最大能有多大?
首先我们知道,一个生成树域不可能很大吧?一个交换区块,里面的交换机的数量也不可能很多吧?
到底能有多少呢?之前提过,最多只能有7台吧?为什么?就是因为这3个计时器的值来的,当一个交换
区块内,运行802.1D的生成树协议,并且这3个计时器的值没有被修改过,这时候官方定义的,使用
这3个缺省计时器能够支持的最大拓扑直径只能有7跳,如果拓扑直径>7,生成树可能会无法收敛
我们为了收敛速度更快,可以更改这3个计时器的值,注意这个值只需要在根桥修改就可以了
生成树的初始收敛时间为30秒,发生直接性拓扑变更时重收敛时间为30秒,发生间接性拓扑变更时重收敛时间为50秒,细微性拓扑变更重收敛时间也是50秒
最后说一个小知识,其实802.1D的生成树协议不叫STP,而叫做CST(公有)通用生成树协议、PVST(思科私有)基于VLAN的生成树协议,对于思科的交换机
,只能启用PVST,对于华为的交换机只能启用CST,它们的区别就是基于VLAN,CST不支持VLAN,PVST支持VLAN
举个例子,交换机部署VLAN干嘛的?划分广播域吧?一台交换机上理所应当应该有多个VLAN吧?但如果你的交换机是华为的交换机,那么只能运行CST,而
,CST就会造成不管部署了多少个VLAN,只要你交换机运行了CST,那么所有VLAN的成员只能使用相同的生成树路径来转发报文
什么意思?例如3台交换机都有VLAN10,VLAN20,这时候如果运行CST生成树,那么所有的VLAN(也就是1~4094)共享同一个生成树进程,那么所有的VLAN流量都不能在被阻塞的链路上传输
而对于PVST而言,每一个VLAN都可以指定一个生成树进程,这样例如,对于VLAN10而言,它的其中一根链路阻塞掉以后,不会影响其他VLAN,也就是说VLAN20
对于它而言,它不知道VLAN10的那根链路被阻塞,VLAN20的流量依然可以通过那根被阻塞的链路传输,也就是说VLAN10的阻塞信息对于其他VLAN是透明的
这样做的好处是更灵活,能够减少延迟,但是它会有多个生成树进程,维护的开销比较大,CPU的消耗会比较大,CPU可能会扛不住
那有没有一种方法,能够让一个生成树协议对应多个拥有相同属性的VLAN或一个VLAN呢?,这就是MSTP(802.1S多生成树协议)
关于PVST,PVST不是基于VLAN的生成树协议吗?一个进程对应一个VLAN,那理所应当的默认情况下每一个进程隔2秒都会发送一个BPDU报文吧?
那问题来了,一个交换机在收到一个BPDU报文的时候,它怎么知道这个报文是来自于哪个VLAN呢?答,思科在BPDU报文中的Bridge ID字段中
,把前面2个字节的优先级值逻辑的划分成了2个子字段,第一个字段占4bit(比特),依然是优先级,后面12bit,称之为扩展系统ID,它的取值范围
是0~4095,而交换机能创建的VLAN是1~4094,所以这些值已经能够给每个VLAN打上一个标记了,这样交换机就知道这个BPDU是来自哪个VLAN的了
因为这个扩展系统ID是那两个字节的子字段,所以默认情况下开起了扩展系统ID后,也会影响到Bridge ID的值
默认情况下低端交换机(这里说的描述高低端是从背板带宽,和背板MAC地址的数量来区分的),高端交换机,当一个交换机的背板MAC地址<=1024个
这时候交换机运行PVST的时候,默认这个扩展系统ID默认是开启的,如果>1024个,默认运行PVST,是不会开启扩展系统ID的,对于交换区块而言
肯定有的交换机开启了扩展系统ID,有的没开启,那么对于开启了扩展系统ID的交换机就不占优势了,因为它们的Bridge ID会比较正常没开启的
要高,从而失去了选举的机会,所以建议一个交换区块内,建议全部开启扩展系统ID
CST和PVST的混合操作,一家企业可能部署的有不同的厂商生产的设备,如果一个交换区块内,有不同厂商的交换机那生成树协议会无法兼容
因为思科交换机只能运行PVST,而华为交换机只能运行CST,这时候怎么办呢?答:思科做了一个贡献,它对PVST进行了一个升级,把它取了一个
新名字,叫做PVST+,现金IOS上面跑的生成树协议都是PVST+,默认开启的也是PVST+,PVST+是可以和CST互相操作的,所以说部署生成树协议的
时候不用担心混合厂商的场景
配置命令相关:
SW1(config)#spanning-tree mode ? //开启生成树
SW1(config)#spanning-tree vlan 10 //基于VLAN开启生成树
SW1(config)#spanning-tree extend system-id //开启扩展系统ID
SW1#show spanning-tree //查看生成树信息
SW1#show spanning-tree vlan 10 //查看指定VLAN的生成树信息
SW1(config)#spanning-tree vlan 10 priority 8192 //修改该交换机关于VLAN10进程的优先级改为8192
SW1(config)#spanning-tree vlan 20 root primary //让该将交换机成为VLAN20的主根桥,这是个宏命令
SW1(config)#spanning-tree vlan 20 root secondary //让该将交换机成为VLAN20的备份根桥,这是个宏命令
SW1(config)#int e0/0
SW1(config-if)#spanning-tree vlan 20 cost 40 //将该交换机的e0/0接口的入站路径代价更改为40
SW1(config-if)#spanning-tree vlan 20 port-priority 112 //修改该接口对于VLAN20的生成树的Port ID为112,注意一定要能被16整除
CCNA中交换最后一部分,交换安全
什么叫安全?
物理安全:人祸,天灾
逻辑安全:数据流量的安全,逻辑安全就是要保证数据流量在网络中传输的时候不被窃听,不被盗取,不被篡改
基本密码配置:
Console Password:
SW1(config)#line console 0
SW1(config-line)#password cisco
SW1(config-line)#login
Virtual Terminal Password:
SW1(config)#line vty 0 4
SW1(config-line)#password cisco
SW1(config-line)#login
Enable Password(以明文方式设置密码):
SW1(config)#enable password cisco
Secret Password(以密文方式设置Enable密码):
SW1(config)#enable secret cisco
Service Password-Encryption Commands(对所有能够配置密码的地方都采用密文形式):
SW1(config)#servic password-encryption
SW1(config)#no service password-encryption
交换机的端口安全
端口安全是一个基于接口的安全机制,一般只能部署在交换机的二层接口之上,并且只能工作在Access模式上.
1.它有什么用?
在描述它的作用前,我们先分析一个问题,首先,我们的交换机是通过看表转发数据帧,通过自动学习的方式,可以根据接收到的数据帧的源MAC地址,来进行自动看表项填充
那么问题来了:
(1).交换机的一个接口最多能学习到多少MAC地址表项?答,理论上是没有限制的
(2).交换机获悉看表项的方式有2种,一种是手工键入,一种是自动学习,那么手工键入的看表项能在看表中维持多长时间呢?答,手工键入是永久,自动学习是300秒
(3).交换机的看表的条目有没有限制,换句话说交换机的看表是不是无限大?答,不是,交换机的看表条目是有限的,因为交换机的内存是有限的
2.基于上面的问题,那么我们来看一种攻击方式:
那么有一种攻击叫做看表的范洪攻击,该攻击方式就是在每发送一个数据帧之前,将源MAC地址修改为一个随机的MAC地址,这会导致交换机不停的学习MAC地址
,这时候几秒内可能交换机的看表就已经被占满,那么交换机将无法再学习MAC地址,这时候,如果交换机再次收到数据帧,那么他会在VLAN内范洪
,这时候,同VLAN内的其他PC发送数据帧也会被范洪,那么问题来了,如果这时候黑客开一个抓包软件,他能抓到什么?
那么基于上面的攻击,怎么解决?
实现上面的攻击的归根结底的原因是上面的问题(1),就是因为无穷无尽这一点导致交换机可以被利用这个漏洞来攻击
怎么解决?答:限制交换机一个接口最多能学习到的MAC地址表项,这个机制就是我们的端口安全,一般情况下端口安全部署在接入层,因为接入层就是直接连PC或服务器的
注意:
一旦一个接口启用端口安全特性,那么这个接口会生成两张表,一个叫做白名单地址表,一个叫做黑名单地址表,缺省这两张表是空的
能通过什么机制填充这两张表?要么手工键入,要么自动学习
无论是手工键入还是自动学习,最先获得的MAC地址信息都会先放入白名单,等白名单满了,新的地址信息才会放入黑名单
当交换机收到一个数据帧它先会检查该帧头的源MAC地址是否存在与白名单,如果是则放行,否则要么丢弃,要么将该接口shutdown,这个我们称之为惩罚策略
关于惩罚策略:
一个接口如果惩罚策略是shutdown,那么该接口如果被惩罚,就会被置为一个叫做error disable状态,这个状态你就可以把它理解为shutdown状态,它不能收发任何报文
,包括BPDU,默认情况下这个error disable状态是不会自动恢复的,除非你手动配置命令,或到这个接口下shutdown后再no shutdown来让它强制还原到正常转发状态
惩罚机制有:
protect //丢弃
restrict //丢弃并将日志发送给日志服务器
shutdown //关闭接口直接将接口置为error-disable
注意:黑白名单和看表的超时时间是一样的,手工键入是永久,自动学习是300秒,如果这个接口down了,那么从这个接口学习到的MAC地址信息会从看表和黑白名单中全部被删除
3.接下来我们来看第二种攻击方式:
假设我们在一个交换区块中,一个汇聚层交换机下面有多台接入交换机,汇聚层和接入层都开启了端口安全,采用的都是自动学习的方式,这时候,如果一个黑客
到汇聚交换机所在的地方,将汇聚交换机连接到核心交换机之间的网线,插到自己的PC上会产生什么后果?我们上面说过,当一个接口down了,那么从这个接
口学习到的MAC地址信息会从看表和黑白名单中全部被删除,那么当网线被拔下来的时候状态会变为down,那么之前交换机的合法MAC地址会被删除,再插到黑客
的PC上,这时候交换机会重新自动学习MAC地址信息,并加入白名单,所以黑客的PC这时候会变为合法MAC地址,那么黑客这时候对内网实施攻击就是易如反掌了.
那么基于上面的攻击,怎么解决?
我们可以利用手动键入MAC地址的方式来,防止该攻击,将核心交换机的MAC地址手动写入到白名单,这样就可以防止上面的攻击方式了,但是我们说过手工键入的方式
不灵活,不利于我们管理,因为手工键入MAC地址后,那么永远就必须连接到该接口上,那有没有一种折中的方式?能够自动学习,而在接口down掉后,又不会自动删除
该MAC地址表项?答,有,就是我们的粘性端口安全.什么是粘性端口安全,就是交换机一个接口所学习到的第一个MAC地址会以手动键入的方式保存在白名单中,当
接口down掉时,该MAC地址表项不会删除
一些建议:
(1).当能使用SSH的时候尽量使用SSH,而不要使用Telnet
相关配置命令:
SW1#show mac address-table //查看交换机的看表
SW1#show mac address-table aging-time //查看看表的超时时间
SW1(config-if)#switchport port-security //启用端口安全特性
SW1#show port-security interface ethernet 0/0 //查看接口端口安全的一些摘要信息
SW1#show port-security address //查看白名单地址信息
SW1(config-if)#switchport port-security mac-address AAAA.BBBB.CCCC //手工输入白名单MAC地址
SW1(config)#errdisable recovery cause psecure-violation //开启端口安全自动恢复
SW1(config)#errdisable recovery interval 60 //60秒后自动恢复
SW1(config-if)#switchport port-security mac-address sticky //启用粘性MAC地址学习
SW1(config-if)#switchport port-security maximum 1 //设置白名单中最多能存放多少条MAC地址
SW1(config-if)#switchport port-security violation ? //设置惩罚策略
DHCP协议
它是一个应用层协议,DHCP基于UDP端口号68
DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)是一个局域网的网络协议,使用UDP协议工作
,主要有两个用途:给内部网络或网络服务供应商自动分配IP地址,给用户或者内部网络管理员作为对所有计算机作中央管理的手段
DHCP协议有4个类型的报文:
discover:发现报文,这是一个广播报文,用于客户端在本网段查找DHCP服务器时使用
offer:应答报文,这是一个单播报文,DHCP服务器在收到discover报文时应答使用
request:请求报文,这是一个广播报文,用于客户端告知第一个接收到offer报文的DHCP服务器,想要使用其分配的IP地址
,和告知其他DHCP服务器,回收它们的IP地址
acknowledgment:确认报文,这是一个单播报文,用于DHCP服务器告知DHCP客户端,确认客户端要使用其IP地址,并且下发相应的IP地址信息
相关配置命令:
SW1(config)#service dhcp //开启DHCP服务
SW1(config)#int e0/0
SW1(config-if)#ip address 12.1.1.254 255.255.255.0 //要使用DHCP服务,接口必须要有地址
SW1(config-if)#no shutdown
SW1(config)#ip dhcp pool test-dhcp-name //进入DHCP配置模式
SW1(dhcp-config)#network 12.1.1.1 255.255.255.0 //指定要分发的IP地址段
SW1(dhcp-config)#default-router 12.1.1.254 //指定分配网关
SW1(dhcp-config)#lease 1 0 0 //设定DHCP租约时间为1天
SW1(config)#ip dhcp excluded-address 12.1.1.253 12.1.1.254 //12.1.1.253到12.1.1.254排除,不分配
SW1(config-if)#ip address dhcp //接口使用DHCP获得地址
VLSM(IP地址规划)
子网掩码与主机数量对应关系表(如下):
掩码 对应二进制 对应主机数
30 ---- 1111 1111 1111 1111 1111 1111 1111 1100 -------> 4(实际可用数量-2)
29 ---- 1111 1111 1111 1111 1111 1111 1111 1000 -------> 8(实际可用数量-2)
28 ---- 1111 1111 1111 1111 1111 1111 1111 0000 -------> 16(实际可用数量-2)
27 ---- 1111 1111 1111 1111 1111 1111 1110 0000 -------> 32(实际可用数量-2)
26 ---- 1111 1111 1111 1111 1111 1111 1100 0000 -------> 64(实际可用数量-2)
25 ---- 1111 1111 1111 1111 1111 1111 1000 0000 -------> 128(实际可用数量-2)
24 ---- 1111 1111 1111 1111 1111 1111 0000 0000 -------> 256(实际可用数量-2)
23 ---- 1111 1111 1111 1111 1111 1110 0000 0000 -------> 512(实际可用数量-2)
22 ---- 1111 1111 1111 1111 1111 1100 0000 0000 -------> 1024(实际可用数量-2)
21 ---- 1111 1111 1111 1111 1111 1000 0000 0000 -------> 2048(实际可用数量-2)
20 ---- 1111 1111 1111 1111 1111 0000 0000 0000 -------> 4096(实际可用数量-2)
19 ---- 1111 1111 1111 1111 1110 0000 0000 0000 -------> 8192(实际可用数量-2)
18 ---- 1111 1111 1111 1111 1100 0000 0000 0000 -------> 16384(实际可用数量-2)
17 ---- 1111 1111 1111 1111 1000 0000 0000 0000 -------> 32768(实际可用数量-2)
16 ---- 1111 1111 1111 1111 0000 0000 0000 0000 -------> 65536(实际可用数量-2)
15 ---- 1111 1111 1111 1110 0000 0000 0000 0000 -------> 131072(实际可用数量-2)
14 ---- 1111 1111 1111 1100 0000 0000 0000 0000 -------> 262144(实际可用数量-2)
13 ---- 1111 1111 1111 1000 0000 0000 0000 0000 -------> 524288(实际可用数量-2)
12 ---- 1111 1111 1111 0000 0000 0000 0000 0000 -------> 1048576(实际可用数量-2)
11 ---- 1111 1111 1110 0000 0000 0000 0000 0000 -------> 2097152(实际可用数量-2)
10 ---- 1111 1111 1100 0000 0000 0000 0000 0000 -------> 4194304(实际可用数量-2)
9 ---- 1111 1111 1000 0000 0000 0000 0000 0000 -------> 8388608(实际可用数量-2)
8 ---- 1111 1111 0000 0000 0000 0000 0000 0000 -------> 16777216(实际可用数量-2)
7 ---- 1111 1110 0000 0000 0000 0000 0000 0000 -------> 33554432(实际可用数量-2)
6 ---- 1111 1100 0000 0000 0000 0000 0000 0000 -------> 67108864(实际可用数量-2)
5 ---- 1111 1000 0000 0000 0000 0000 0000 0000 -------> 134217728(实际可用数量-2)
4 ---- 1111 0000 0000 0000 0000 0000 0000 0000 -------> 268435456(实际可用数量-2)
3 ---- 1110 0000 0000 0000 0000 0000 0000 0000 -------> 536870912(实际可用数量-2)
2 ---- 1100 0000 0000 0000 0000 0000 0000 0000 -------> 1073741824(实际可用数量-2)
1 ---- 1000 0000 0000 0000 0000 0000 0000 0000 -------> 2147483648(实际可用数量-2)
VLSM:把一个主类地址段,通过多次借位,划分出了若干个掩码长度不一的子网段
在一个园区网部署VLSM需要注意一些什么? 案例分析:
(1).分析企业网到底有多少个广播域,因为知道有多少个广播域后我们才能知道最少我们要借多少位
例子:给你一个子网177.177.0.0/16,现在网络中有11个广播域,
解答:给定你一个子网,知道网络中有多少个广播域后,我们最少就知道要借多少位主机了,
对于本题,现在的网络位是16,我们要以它为基础,划分出11个子网,那怎么划分呢?
16对应的主机数量是65536,那么我们要让65536除以11,这样平均分出来每个子网需要
65536 / 11 = 5957.818... 个主机,那哪个网络位满足并且最不浪费地址呢?
答:19,这样我们就知道最少要借多少位了, 19 - 16 = 3,也就是说你最少要借3位来做网络位
(2).分析企业网中最大的广播域需要多少个节点
(1).第一个广播域需要210台主机可用
(2).第二个广播域需要128台主机可用
(3).第三个广播域需要90台主机可用
(4).第四个广播域需要70台主机可用
(5).第五个广播域需要64台主机可用
(6).第六个广播域需要50台主机可用
(7).第七个广播域需要33台主机可用
(8).第八个广播域需要15台主机可用
(9).第九个广播域需要2台主机可用
(10).第十个广播域需要2台主机可用
(11).第十一个广播域需要2台主机可用
对于本题:告诉你了一个广播域最大需要210台主机,那么为了满足地址最少浪费的原则,上面的借3
位来做网络位就不可用了,因为广播域最大才需要210台,你19位是8000多台,这就造成了极大的浪费
所以我们要看哪个网络位离210最近,并且能满足它,那就是24
(3).根据(2)的分析,对主类地址段进行第一次子网化
对于本题:第一次子网化网络位为24
,那么第一个子网就是177.177.0.0/24
,那么最后一个子网就是177.177.255.0/24
为什么最后一个子网是255.0? 因为原来的16网络位对应的主机是65536,你现在要把它按照24网络位划分,那么24网络位对应的主机数量是256
65536 / 256 = 256个子网,分别是从0 ~ 255,所以最后一个子网是255.0
(4).从小到大的顺序把划分出来的子网段分配给相应的广播域
对于本题:
,那么第一个子网就是177.177.0.0/24 ---> 那么这个子网就拿给"(1).第一个广播域需要210台主机可用"使用
,那么第二个子网就是177.177.1.0/24 ---> 那么这个子网就拿给"(2).第二个广播域需要128台主机可用"使用
(5).把最后一个子网段保留用于下一次子网化使用
对于本题:
,最后一个子网就是177.177.255.0/24 将它保留用以下一次子网化
对于本题,剩下的划分方法:
对于90个节点,24太大,26太小,所以取值为25,用上一次划分保留的最后一个子网再次划分,177.177.255.0/24:
24 = 256,25 = 128; 256 / 128 = 2个子网,也就是说177.177.255.0/24,如果按25位来划分,最多能划分出2个子网,
那么第一个子网为:177.177.255.0/25,第二个子网为:177.177.255.128/25,将第一个子网给90个节点,还剩一个子网.
对于70个节点,24太大,26太小,所以取值为25,
将上面保留的177.177.255.128/25,用来再次子网化
25 = 128,25 = 128; 128 / 128 = 1也就是说如果取值为25,那么对于这个子网来说就不能再划分了,直接将该子网给它用就可以了
将177.177.255.128/25给70个节点,那么对于177.177.255.0/24子网来说,可划分的子网就没有了,已经用完了
对于64个节点,24太大,26太小,所以取值为25,
因为上面177.177.255.0/24已经被划分完了,所以只能用24子网中的其他子网来划分,一般建议按从后到前的顺序来使用
,也就是255.0的前面一个254.0,我们可以用它来再次划分子网177.177.254.0/24
24 = 256,25 = 128; 256 / 128 = 2个子网,也就是说177.177.254.0/24,如果按25位来划分,最多能划分出2个子网,
那么第一个子网为:177.177.254.0/25,第二个子网为:177.177.254.128/25,将第一个子网给64个节点,还剩一个子网.
对于50个节点,25太大,27太小,所以取值为26,
将上面保留的最后一个子网177.177.254.128/25,用来再次划分,
25 = 128,26 = 64; 128 / 64 = 2个子网,也就是说177.177.254.128/25,如果按25位来划分,最多能划分出2个子网,
分别是:177.177.254.128/26,和177.177.254.192/26,将第一个子网177.177.254.128/26分给50个节点使用,还剩一个
子网177.177.254.192/26,保留用以下次子网化
对于33个节点,25太大,27太小,所以取值为26,
将上面保留的177.177.254.192/26,用来再次子网化
26 = 64,26 = 64; 64 / 64 = 1 也就是说如果取值为26,那么对于这个子网来说就不能再划分了,直接将该子网给它用就可以了
将177.177.254.192/26给33个节点,那么对于177.177.254.128/25子网来说,可划分的子网就没有了,已经用完了
对于15个节点,26太大,28太小,所以取值为27,
因为上面已经没有保留给我们用以再次划分的子网了,所以我们还要从上一级再拿出一个更大的子网来划分了,那就是177.177.253.0/24
24 = 256,27 = 32; 256 / 32 = 8个子网也就是说177.177.253.0/24,如果按27位来划分,最多能划分出8个子网
,那么第一个子网为177.177.253.0/27,第二个子网为177.177.253.32/27,第三个子网为177.177.253.64/27...
最后一个子网为:177.177.253.224/27,我们将第一个子网177.177.253.0/27给15个节点使用
,然后我们保留最后一个子网,用以下一次子网化
对于2个节点,所以取值为30,
用上面保留的最后一个子网来再次子网化177.177.253.224/27
27 = 32,30 = 4; 32 / 4 = 8个子网也就是说177.177.253.224/27,如果按30位来划分,最多能划分出8个子网
,那么第一个子网为177.177.253.224/30,第二个子网为177.177.253.228/30,第三个子网为177.177.253.232/30
分别将这三个子网分配给最后三个2节点的广播域,然后保留最后一个子网用以下一次子网化.
最后划分的结果就是:
(1).第一个广播域需要210台主机可用:177.177.0.0/24
(2).第二个广播域需要128台主机可用:177.177.1.0/24
(3).第三个广播域需要90台主机可用:177.177.255.0/25
(4).第四个广播域需要70台主机可用:177.177.255.128/25
(5).第五个广播域需要64台主机可用:177.177.254.0/25
(6).第六个广播域需要50台主机可用:177.177.254.128/26
(7).第七个广播域需要33台主机可用:177.177.254.192/26
(8).第八个广播域需要15台主机可用:177.177.253.0/27
(9).第九个广播域需要2台主机可用:177.177.253.224/30
(10).第十个广播域需要2台主机可用:177.177.253.228/30
(11).第十一个广播域需要2台主机可用:177.177.253.232/30
最后提一下相关公式:
(1).计算最后一个子网是什么:
对于子网掩码是24位~30位的计算方式:
256 - 当前子网对应的主机数量
例如,177.177.255.0/24,你要按照24来划分子网,那么256 - 256对应的主机数量(256), = 0,那么它最后一个子网就是177.177.255.0/24
例如,177.177.255.128/25,你要按照25来划分子网,那么256 - 25对应的主机数量(128), = 128,那么它最后一个子网就是177.177.255.128/25
例如,177.177.255.128/26,你要按照26来划分子网,那么256 - 26对应的主机数量(64), = 192,那么最后一个子网就是177.177.255.192/26
对于子网掩码是24位以下的计算方式:
首先死记硬背一个概念, 256 = 0;
256 - (当前子网对应主机数量 / 256)
例如,177.177.0.0/16,你要按照16来划分子网,那么256 - (16对应主机数量(65536) / 256 = 256) = 0,那么它的最后一个子网就是177.177.0.0/16
例如,177.177.0.0/17,你要按照17来划分子网,那么256 - (17对应主机数量(32768) / 256 = 128) = 128,那么它的最后一个子网就是177.177.128.0/17
例如,177.177.0.0/18,你要按照18来划分子网,那么256 - (18对应主机数量(16384) / 256 = 64) = 192,那么它的最后一个子网就是177.177.192.0/18
(2).计算能划分出多少个子网:
当前子网对应主机数 / 你要划分的子网对应主机数
例如,177.177.0.0/16,你要按照17来划分子网,那么16对应主机数(65536) / 17对应主机数(32768) = 2,也就是说,177.177.0.0/16你如果按照17来划分子网最多只能划分出2个子网
例如,177.177.0.0/16,你要按照24来划分子网,那么16对应主机数(65536) / 24对应主机数(256) = 256,也就是说可以划分出256个子网
CIDR(无类域间路由)
什么是无类?
什么是有类?
前面说过部署VLSM可以节约IP地址,但是它也同时带来了另一层隐患,因为部署了VLSM后,网段数量会越来越多
,网段数量越来越多会导致路由器的路由表会越来越大,路由表越来越大又会导致转发延迟越来越高,转发延迟
越来越高,会导致用户体验越来越差,那我们有没有什么方式能够让路由表的条目稍微的小一点呢?答,有,这种
方式就叫做路由汇总,什么叫路由汇总:将拥有相同下一跳地址,相同出站接口的,连续的子网路由通过某种方式
,让它合并在一起,形成一个大的路由条目这就叫做路由汇总,路由汇总就是VLSM的反操作
路由汇总的条件:
(1).要被汇总的路由条目必须是连续的(连续是指:1,2,3,4,5,6,......)
(2).路由器发包使用相同的出站接口,发给相同的下一跳地址
路由汇总:就是把多条小的子网段汇总成一个大的子网段,或者把多个大的子网段汇总成一个主类网段,节约路由器的CPU和内存资源
路由聚合:就是把多个主类网段汇聚成一个超网(就是<24掩码的)
路由汇总的方法:
(1).将需要汇总的ip地址转换为二进制表示形式
(2).然后看看前面多少位是不变的,将前面不变的位数保留
(3).后面要变的全部置为0
注意:ip地址,xxx.xxx.xxx.xxx,一个xxx为8位组成
案例1:
192.168.01000000.1 192.168.64.1 24
192.168.01010000.1 192.168.80.1 24
192.168.01100000.1 192.168.96.1 24
192.168.01110000.1 192.168.112.1 24
192.168.01是不变的,也就是前面18位不变,那么后面是会变化的,我们把它全部置为0
那么汇总后的ip就是:192.168.64.0/18
上面的例子是一个不好的例子,因为汇总的路由条目不是连续的,这会造成路由黑洞什么是路由黑洞
,就是你将不连续的网段汇总之后,其中包含的其它网段,路由器可能并不知道怎么去,或者说路由器
并没有连接到那些网段的接口,这样如果一个路由条目去往的地址是汇总后包含,但是路由器又没有
连接不知道该怎么走的报文,这时候路由器会直接将该报文丢弃,而发送者并不知道对端路由器丢弃
了它的报文,它以后可能还会继续发送,而对端路由器会继续丢弃,这就叫做路由黑洞
比较精确比较好的路由汇总案例,案例2:
192.168.00000000.1 192.168.0.1 24
192.168.00000001.1 192.168.1.1 24
192.168.00000010.1 192.168.2.1 24
192.168.00000011.1 192.168.3.1 24
汇总后的结果:
192.168.0.0/22
注意看,汇总后的掩码是22,22对应的主机数是1024个主机,而一个网段最多256台
我们汇总就刚好是把上面4个网段汇总成一个网段192.168.0.0/22,而如果目的网段
是到192.168.5.0/22或以上网段的路由的话,就是另一个广播域了,所以我们这个路由
汇总是精确汇总,不会出现找不到地址而丢弃的问题,所以由这一点可以看出,一个精确路由汇总
一定要是被汇总条目是连续的,否则会出现路由黑洞
ARP协议
在研究ARP之前,先分析一个问题,我们已经知道数据流在网络中传输无非两种情况,一个是在广播域之内传递,一个是在广播域之间传递
,那么我们PC上网需要有什么条件?首先网卡需要有IP地址吧?需要有子网掩码吧?需要有网关吧?需要有DNS服务器吧?那么问题来了
,当一台PC想要实现广播域内通信的时候需不需要网关?那么首先您一个问题,什么叫做网关?对于一个广播域而言,连接这个广播域的路由器
的直连接口的ip地址就是网关,所以说对于广播域内的通信是不需要网关的,因为流量并没有跨越广播域,所以不需要通过路由器进行路由,而通过
交换机就可以转发报文了,只有当跨越广播域通信的时候,我们才需要指定网关,因为PC根本不知道到达其他广播域的路径该怎么走,这时候
PC就直接把报文发给网关,叫网关帮助解决这个问题.那现在来了一个问题,"我"PC想要发包,"我"怎么知道这个包是发给同一个网段还是跨越网段发送呢?
判断这个的方法很简单,就是用"我"本地接口的子网掩码和目的ip地址做一个逻辑与运算,得出的值如果是和"我"属于同一个地址段,那么它
就是本网段的报文,否则就是跨网段的报文.
接下来在看一个问题:
当"我"想要发送一个报文给同网段的PC的时候,"我"能不能不管3721,直接把报文发送给交换机?答案,是不行是吧?那么我们想要发送报文
需要哪些条件呢?首先需要封装ip地址信息对吧?然后在二层还要封装以太网帧头(MAC地址信息)才能被发送吧?那么问题来了?现在"我"只
知道目的IP地址,不知道目的MAC地址,"我"又怎样形成以太网帧发给你呢?
接下来就引入一个协议叫做ARP协议:
ARP协议称之为地址解析协议,它是一个三层协议,它的作用只有一个,就是让一台PC在访问网段内的其它PC之前能够通过该协议的报文交互来
获悉目的PC的MAC地址的信息.
ARP一共只有2种报文,一个我们称之为ARP Request,一个我们称之为ARP reply.当A和B之间通过交换机互联,当A想要和B通信的时候,首先A会给B发送
一个ARP Request报文,而B会给A回复一个ARP reply报文,当A收到这个报文后会将B的MAC地址信息与B的IP地址信息做一个绑定,存储在本地一张
ARP表中,以后A给B发送报文会直接从ARP表中解析MAC地址,形成以太网帧头,发送给交换机,从而进行通信
ARP request:
Sender Hardware Addr //请求者的二层地址
Sender Internet Addr //请求者的三层地址
Target Hardware Addr //被请求者的二层地址
Target Internet Addr //被请求者的三层地址
ARP IP报头:
Source IP //源IP
Destination IP //目的IP
ARP 以太网帧头:
Source MAC //源MAC
Destination MAC //目的MAC
接下来看,如果A发送了一个ARP请求给B,SMAC=A的MAC,DMAC=FF:FF:FF:FF:FF:FF:FF(全向广播),SIP=A的IP,DIP=B的IP
,Sender Hardware Addr=A的MAC地址,Sender Internet Addr=A的IP地址,Target Hardware Addr=00:00:00:00:00:00(未指定地址)
,Target Internet Addr=B的IP地址,这个ARP request是一个广播,是A在询问"我"想要发送报文给"你"B,但由于"我"不知道"你"
的MAC地址请"你"告诉"我","你"的MAC地址是什么?
当B收到这个ARP请求的时候,B会先把A的IP地址和MAC地址做一个绑定,存入自己的ARP表中,然后才会给A返还一个ARP reply报文
而这个ARP reply报文是一个单播报文,它包含Sender Hardware Addr(这里叫做应答者的二层地址),以及Sender Internet Addr(这里叫做应答者的三层地址)
,和Target Hardware Addr(这里叫做请求者的二层地址),Target Internet Addr(这里叫做请求者的三层地址)
分别是:
Sender Hardware Addr = B自己的MAC地址
Sender Internet Addr = B自己的IP地址
Target Hardware Addr = A的MAC地址
Target Internet Addr = A的IP地址
注意ARP报文一个是广播(ARP request),一个是单播(ARP reply)
最后问大家一个问题?ARP表中的表项能够存储多长时间?答,ARP表超时时间为4小时,ARP表通过自动学习来填充,也可以通过管理员手动配置来填充
,管理员手动填充的ARP表项的超时时间为永久,PC的ARP表可以通过arp -a来查看
相关配置命令:
SW1#show arp //查看ARP表
SW1#clear arp-cache //清空ARP表
SW1#debug arp //开启ARPDebug
SW1#ping 12.1.1.1 //当开启了ARPDebug后,通过Ping就能看到过程
SW1(config)#ip default-gateway 12.1.1.254 //设置网关
Router(config)#ip gratuitous-arps //开启免费ARP
关于代理ARP
为了让那些没有指定网关的PC,能够实现跨越网段的通信.
当一台三层设备满足以下3个条件的时候,代理ARP才会正常工作
(1).路由器收到一个ARP请求,首先必须要拥有被请求者所在网段的路由条目
(2).路由器收到ARP请求一定要判断请求者和被请求者不在同一个广播域
(3).接受到ARP请求的接口必须开启代理ARP
当一台PC没有指定网关,还想要访问其他网段的节点时,我们的中间设备只要满足以上3个条件,就会用接收到ARP请求的接口的MAC地址作为ARP应答响应给请求者
关于免费ARP,什么是免费ARP?
免费ARP的作用就是在本机IP地址发生变动的时候,通知网段内的其他节点我的IP地址发生了变动,请你们立即更新关于我的IP地址和MAC地址的映射.
那么免费ARP包含了什么呢?
免费ARP会发送一个ARP request
Sender Internet Addr = 我自己的IP地址
Sender Hardware Addr = 我自己的MAC地址
Target Internet Addr = 我自己的IP地址
Target Hardware Addr = 00:00:00:00:00:00
这样当其他节点收到这个ARP请求的时候就会更新关于"我"的MAC地址映射
当前上面的请求是一个正常的情况下的ARP请求,但如果我是黑客,我现在构造一个下面这样的ARP请求会产生什么效果?
例如"我"所在的网段192.168.1.0/24
第一次发送:
Sender Internet Addr = 192.168.1.1
Sender Hardware Addr = 我自己的MAC地址
Target Internet Addr = 192.168.1.1
Target Hardware Addr = 00:00:00:00:00:00
第二次发送:
Sender Internet Addr = 192.168.1.2
Sender Hardware Addr = 我自己的MAC地址
Target Internet Addr = 192.168.1.2
Target Hardware Addr = 00:00:00:00:00:00
第三次发送:
Sender Internet Addr = 192.168.1.3
Sender Hardware Addr = 我自己的MAC地址
Target Internet Addr = 192.168.1.3
Target Hardware Addr = 00:00:00:00:00:00
第n次发送:
Sender Internet Addr = 192.168.1.n
Sender Hardware Addr = 我自己的MAC地址
Target Internet Addr = 192.168.1.n
Target Hardware Addr = 00:00:00:00:00:00
直到"我"把整个网段的ip都发送一次,这时候会产生什么效果?
答:收到报文的所有节点到网段内所有节点的MAC地址都会更新成"我"的MAC地址,那么它们再发送数据帧,就一定都会走"我"这里过
,如果这时候,"我"开一个抓包软件会抓到什么?可怕吗?
当然免费ARP正常情况下有2个作用
(1).一个就是在IP地址发生变更的时候通知其它节点更新MAC地址映射
(2).还有一个就是当IP地址发生变更的时候发送免费ARP检查IP地址是否冲突,因为免费ARP的请求者IP地址是"我"自己
,被请求者IP地址还是"我"自己,一个网段内"我"的IP只有一个,所以一般情况下,只要没有收到ARP回应,就表示IP
地址没有冲突,反之如果收到了一个ARP应答,证明"我"使用的IP已经有人在使用了.
小小的请求,转载请注明出处,谢谢。